A Unified Framework for Analyzing and Detecting Malicious Examples of DNN Models
A Unified Framework for Analyzing and Detecting Malicious Examples of DNN Models abstract。
Contribution
- 从防御的角度系统研究了对抗样本和后门样本的区别,确定了对抗性和后门示例在对模型突变、激活空间和特征空间中的行为的敏感性方面的异同。
- 应用四种方法检测对抗样本攻击和后门攻击,取得了较好的效果
对抗样本与后门攻击
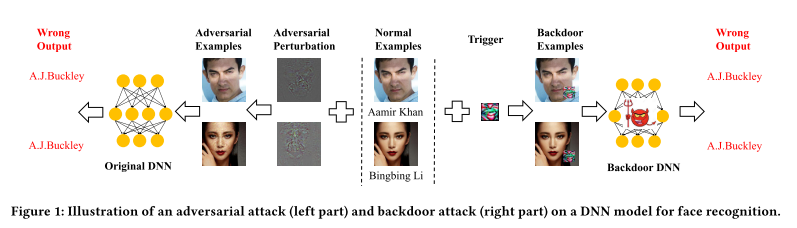
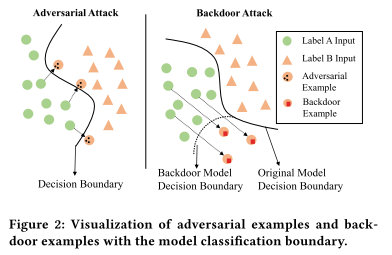
两种攻击的比较:
- 对抗样本是与输入样本绑定的,输入一个样本就需要计算一次扰动;
- 相反,后门攻击中的扰动是固定的;
- 对于特定模型而言,对抗样本攻击是消极的,假设该模型无法被修改。
- 而后门攻击则假设可以修改模型参数,当然修改后的模型在分类正常样本上性能不会受到影响这一点是需要保证的
- 对抗样本是通过添加扰动使得该样本逼近决策边界导致分类错误(扰动根据样本不同而不同的
- 后门攻击的扰动是固定偏移,通过修改模型参数改变决策边界,并通过扰动修改样本点位置,使得分类错误,如可视化图所示
缓解措施
对抗样本缓解措施
对抗样本大致有四种缓解措施:
- 将对抗样本也做为训练数据训练模型
- 设计 AEs-aware 的网络结果或者损失函数
- 模型训练/预测前进行预处理
- 检测对抗样本
后门攻击缓解措施
- 检测/消除后门(边界异常值检测/元神经分析/人工脑刺激
- 识别训练集中的污染数据
- 检测后门样本(得需要后门触发特征已知
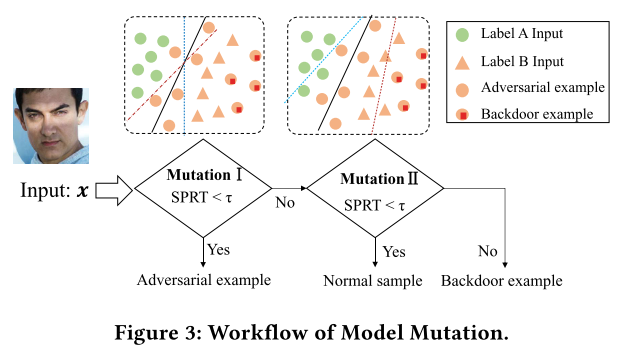
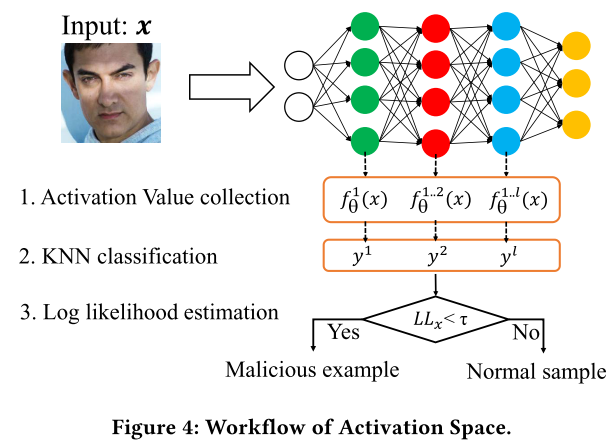
workflow
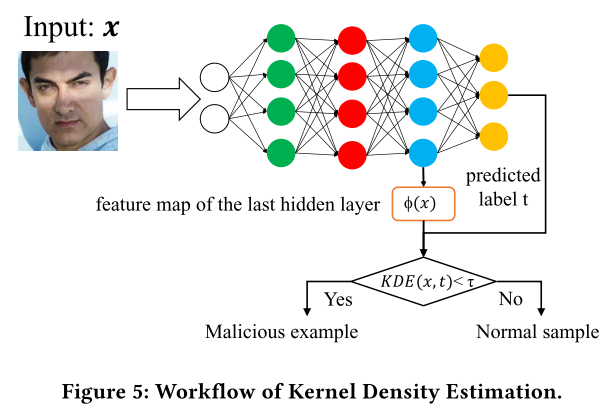
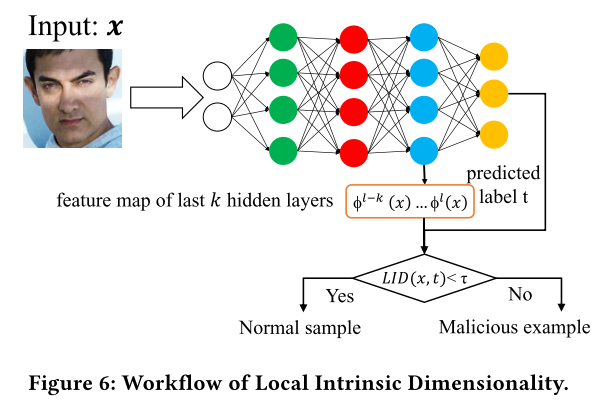
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.