ATLAS: A Sequence-based Learning Approach for Attack Investigation
abstract
1 | In this paper, we present ATLAS, a framework that constructs an end-to-end attack story from off-the-shelf audit logs. Our key observation is that different attacks may share similar abstract attack strategies, regardless of the vulnerabilities exploited and payloads executed. ATLAS leverages a novel combination of causality analysis, natural language processing, and machine learning techniques to build a sequence-based model, which establishes key patterns of attack and non-attack behaviors from a causal graph. At inference time, given a threat alert event, an attack symptom node in a causal graph is identified. ATLAS then constructs a set of candidate sequences associated with the symptom node, uses the sequence-based model to identify nodes in a sequence that contribute to the attack, and unifies the identified attack nodes to construct an attack story. |
文章abstract中指出:
- 提出一个端到端攻击事件构建框架,该框架基于审计日志来进行攻击事件的构建;
- 此框架的主要原理是不同的技术用于实现相同的战术目的;
- ATLAS框架集成了因果分析、自然语言处理和机器学习来构建基于序列的模型,该序列模型是从因果图中识别攻击的主要特征;
- 在推理阶段,给出威胁告警,该框架可以在因果图上识别出攻击节点(attack symptom node);
- 使用识别出的攻击节点可以构建攻击事件和攻击因果图。
本文是发表在信安顶会 USENIX 2021 上的文章,结合了自然语言处理、机器学习方法,值得借鉴学习。源码和数据在:https://github.com/purseclab/ATLAS.
通过案例来解释框架
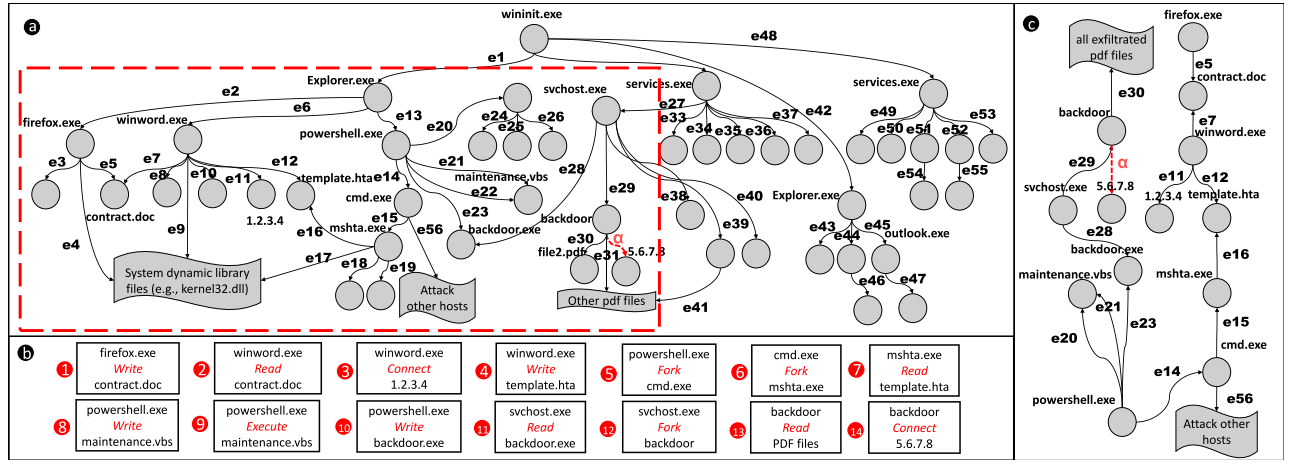
如上图a 所示,框架首先会构建因果图,然后基于因果图进行攻击行为的识别,如虚线红框中的 alpha 虚线所代表的行为即为识别出的攻击。
作者认为在一系列攻击中每个攻击都跟上下文有关,这跟自然语言中每一句话都跟上下文有关是相同的。基于此原理,他们认为提取出的三元组序列可以训练获得在不同APT攻击上有效的模型。因为即使底层的审计记录不同,他们还是拥有相同的上下文语义,或者说战术目的。
在推理阶段会定义攻击节点(attack symptom node),表示这些节点出现在攻击告警中,可能发动攻击行为。以攻击节点为基础,拓展攻击节点的候选节点序列,这些候选节点是跟攻击节点相邻的节点,然后使用模型来识别这些节点是否有助于完成进一步攻击。
如上图中 b 所示,通过这些攻击节点就可以构建攻击事件记录了。而图中 c 则是攻击事件的因果图表示,为完整因果图的子图,描述攻击行为因果关系。
ATLAS架构
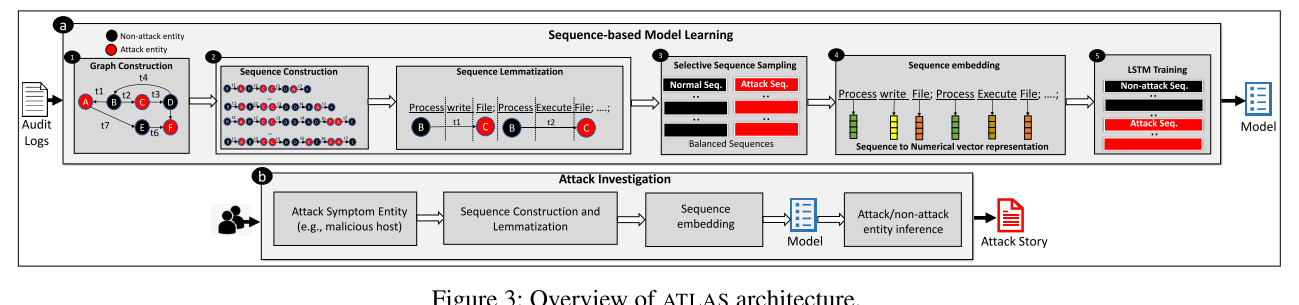
整个 ATLAS 分为两个部分,一个部分是训练,另一个部分是使用该模型进行攻击识别。
在训练部分:
- 审计记录作为输入,从审计记录中抽取实体和关系构建因果图
- 从图中抽取并构建序列
- 对序列进行词形还原
- 选择性序列抽样
- 序列嵌入,将序列转换成数值向量的表示形式
- 将向量送入
LSTM中进行训练得到模型
设计中存在的挑战
-
如何构建序列来对合法活动和可以活动建模
目的是找到更好的序列表示方式,可以更好地区分合法活动和恶意攻击,并且从不同的审计日志类型中提取出来。
在传统的序列提取方式中,存在两个问题,一个是存在着大量的单一实体,比如一个进程具有多个实例;相同的攻击特征出现在不同的进程中会导致不同的序列会出现相同或者极度相似的上下文。
这两个问题会影响模型收敛和学习的精度,可能导致梯度消失或者梯度爆炸。
ATLAS对此进行了图优化,来降低图的复杂度。 -
攻击模型训练时数据集中的非攻击序列过多而攻击序列过少,这是由于攻击和日志的特点导致的
在这样数据集下训练出来的模型会倾向于非公集序列,会导致大量攻击序列未被检测到。
对于此问题,
ATLAS对非攻击序列欠采样对攻击序列过采样,平衡两类攻击的比例。 -
尽管训练好的模型可以进行任意序列的预测,但是输入的序列是专家临时生成的,可能需要大量的序列发现
对于此问题,
ATLAS引入了攻击调查阶段(attack investigate phase),在该阶段将会对审计日志进行攻击识别等操作。因此可以恢复出攻击实体来帮助进行构建攻击事件。
审计日志预处理
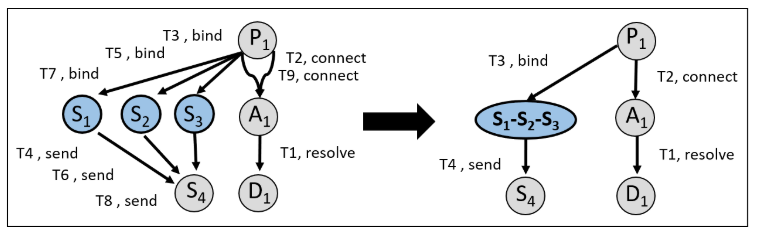
此处解决挑战1中提出的问题,存在大量单一实体,例子是同一个进程具有多个线程实例。在此处将多个节点聚合为一个节点,降低图的复杂度。
为了优化因果图的复杂度,ATLAS 使用了三种方法:取消所有不跟攻击节点相连的点和边;去除所有重复的边;合并同类节点和边。
序列构建和训练学习
在本步骤内会进行:打标签、攻击序列提取、数据平衡采样、词嵌入,然后训练学习。
因果图构建与攻击序列提取

攻击实体子集,集合中全为因果图中攻击实体的集合,且实体个数 <= 2 .
因果图构建与攻击序列提取步骤如下:
- 对于每一个攻击实体子集中的攻击实体, 获得他们的邻居图,此步骤将会使
ATLAS捕获所有与攻击实体有因果关系的实体 ATLAS从邻居图中获取带有时间戳的攻击事件- 将提取出来的带有时间戳的攻击事件转化成攻击序列
非攻击序列的提取与攻击序列相似,但是由于非攻击序列非常多,所以会遇到处理时指数爆炸的问题。而 ATLAS 不会从非攻击序列上学习特征,只会学习攻击学列和非攻击序列的边界。因此在攻击序列中添加一个非攻击节点,这样子会提取出一个非攻击序列。这样子 ATLAS 不但能够获得非攻击序列,而且能够准确地学习到攻击序列和非攻击序列的相似性和不同点。
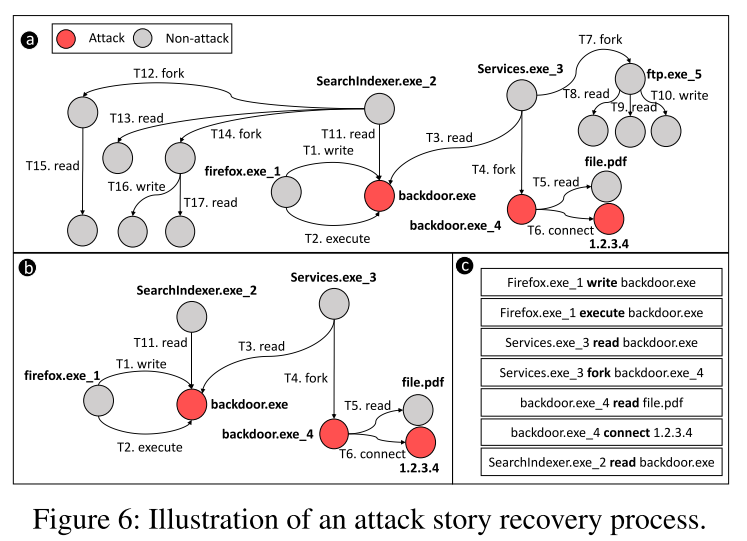
如上图 c 部分,序列 {A, B} 不跟任何事件匹配,所以标记为非攻击序列。
词形还原
ATLAS 使用词形还原的方式将序列转化为归一化的文本来表示序列特征。词形还原在自然语言中常用来处理同一个词的不同形式。如:将 drove 处理为 drive,将 driving 处理为 drive。
这个处理将会获得序列的原始语义,有利于基于序列的模型学习。

举个例子:</system/process/malicious.exe read /user/secret.pdf> is transformed to <system_process read user_file>
这些类型足以捕获因果图中实体的上下文、语义和句法相似性以及与其他单词的关系。
选择性序列取样
为了平衡训练集,ATLAS 首先使用相似度欠采样了非攻击序列,然后使用过采样机制随机变异了攻击序列,最后使得攻击序列数量和非攻击序列数量基本相同。
当然最简单的方法是随机去除非攻击序列和重复攻击序列,但是论文中提及,这样处理会导致模型对攻击序列过拟合并且丢失了重要的非攻击序列的特征。
具体的欠采样的做法如下:
- 欠采样做法通过编辑距离(Levenshtein Distance)来进行样本欠采样,编辑距离用于两个字符串的差异程度的量化测量。以此确保了数据集中去除的是冗余的重复样本。
- 编辑距离通常比较两个字符串之间的差异,在此处
ATLAS计算的是编辑步骤的数量,例如在序列中添加或删除词汇表中的单词,来将序列转换为另一个词形还原序列。以此获得序列的编辑距离。 - 实验发现
80%准确率下的能获得好的采样比和去除高度相似的甚至相同的序列。
具体的过采样方法如下:
- 为了给训练用的攻击序列提供更好的多样性,采用了基于变异的过采样方法。
- 在此项还原表中,有同一类型下的不同子类,如
system_process, program_process。在攻击序列进行词形还原后,将会对其中的实体进行同类型子类的替换。 - 这不会从根本上改变攻击序列,但是增加了在用于模型训练的攻击中未触发的类似序列的数量,由于上下文差异,在其他攻击中仍可能发生。
序列嵌入和模型训练
序列嵌入
ATLAS 在模型训练时结合词嵌入将词形还原后的序列转化成数值向量。常用的词嵌入方式有 word-representing、word2vec,由此生成的词向量可以准确地表示不同词之间的语义关系。序列的向量可以定义了序列实体表中特定域之间的语义关系,有助于在模型训练时突出不同序列的特征。
训练词向量的语料库包含所有从审计日志中提取出来的攻击序列和非攻击序列。
这种序列嵌入的方法相比其他的比如 one-hot-encoding 的方法具有更好的效果。
基于序列的模型训练
ATLAS 使用了 LSTM 网络来学习序列特征。LSTM 是一种常用的模型,并且已经证明在很多基于序列的学习中具有良好的效果。
模型同样包含一个 CNN 网络,该网络可以帮助模型捕获具有隐蔽性和动态变化性的 APT 攻击。模型使用了 dropout 层来降低过拟合并提高泛化性,使用了带 Max pooling 的 Conv1D 层来处理序列,带 Sigmoid 激活函数的全连接层来预测攻击序列关联的可能性。这个模型在试验中获得了相比其他架构更好的准确率。
攻击调查
在此部分就是部署模型进行攻击调查,攻击调查包含攻击实体识别、攻击事件恢复和涉及多主机攻击的处理。
具体效果
数据集:
- 缺少公开数据集,根据公开数据集记录做的
APT攻击复现,并且模拟了正常用户的活动
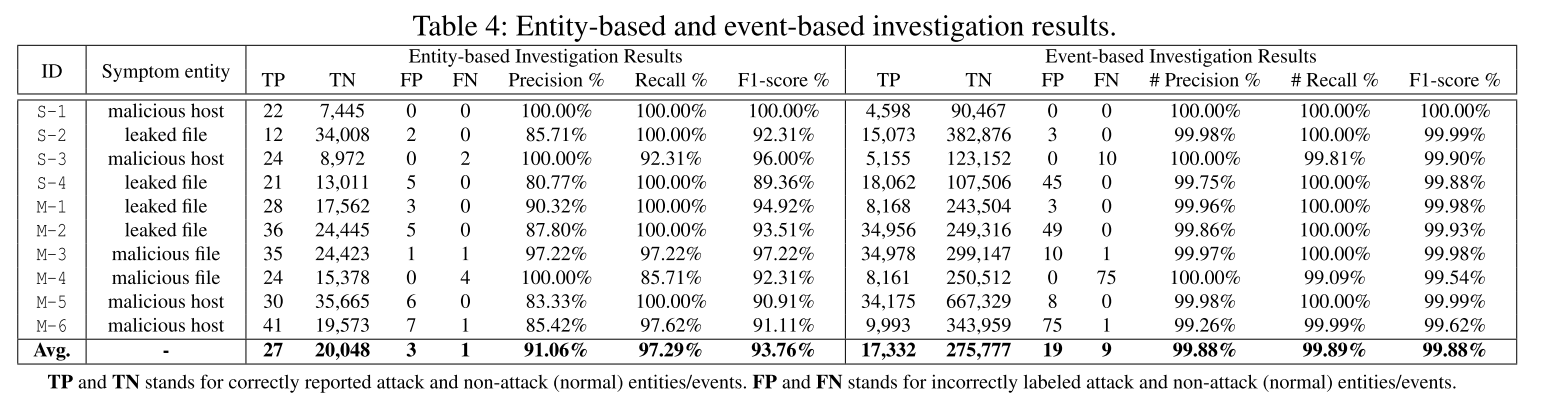
最后,作者分析了结果中的假阳性和假阴性,并且分析了各个组成部分的优化和对于最后结果的支撑。
因果图
定制的因果图生成算法,降低了图的复杂性,有助于改进序列构造的算法。
### 选择性序列采样
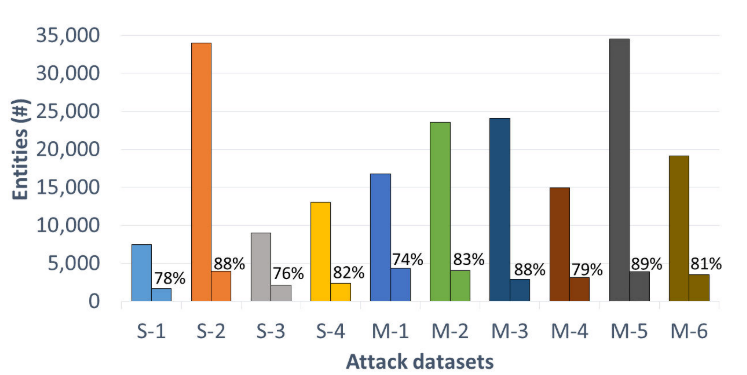
测试结果显示,采样优化后训练时间减少了约 87%。并且非攻击序列的抽取,抽取了初始序列的 22% 左右作为高代表性的训练集,这有效的提高了模型准确率。
总结
作者详细介绍了整个模型的搭建过程和原理,并给出了源码和实验数据:https://github.com/purseclab/ATLAS.
得出结果后,给出了结果假阳性和假阴性的分析,以及模型有效性的分析。
可以参考其模型设计和优化思路,特别是机器学习相关模型中的数据预处理和数据集比例等。最近也在做图神经网络相关的工作,图的设计和生成可以参考此文的优化思路。