数据集异常值检测相关工作调研
数据集异常值检测相关工作。
相关工作
通过几篇文章简单调研投毒攻击与异常值检测相关工作:
Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and DefensesRobust Learning-Enabled Intelligence for the Internet of Things: A Survey From the Perspectives of Noisy Data and Adversarial ExamplesOutlier Detection: Methods, Models, and Classification
Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and Defenses
在 Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and Defenses 中的对抗投毒攻击部分,提到可以通过识别投毒数据和训练阶段阻止投毒样本。除此之外,还提到了针对联邦学习的防御。
文章在该部分建议读者参考下列两篇文章获得更多资料:
V. Barnett and T. Lewis, “Outliers in statistical data,” Wiley Series in Probability and Mathematical Statistics. Applied Probability and Statistics, 1984.A. Boukerche, L. Zheng, and O. Alfandi, “Outlier detection: Methods, models, and classification,” ACM Computing Surveys (CSUR), vol. 53, no. 3, pp. 1–37, 2020.
识别投毒攻击 Identifying Poisoned Data
输入空间内的检测 Outliers in input space
在防御现代机器学习数据集中毒的背景下,J. Steinhardt, P. W. W. Koh, and P. S. Liang, “Certified defenses for data poisoning attacks,” in Advances in neural information processing systems, 2017, pp. 3517–3529. 专注于二进制分类情况并删除远离其各自质心的数据点,该方法直接在输入空间测量或在将数据投影到两个质心之间的线上后测量。
基于假设:如果单个数据点对模型有着很大的影响,它将被识别为异常值。这个假设可以防止攻击者注入一些输入来显著改变模型的行为。以下两篇文章采用鲁棒性均值估计工具(tools from robust mean estimation)来稳健估计数据集上的平均风险梯度(average risk gradient):
I. Diakonikolas, G. Kamath, D. Kane, J. Li, J. Steinhardt, and A. Stewart, “Sever: A robust meta-algorithm for stochastic opti- mization,” in International Conference on Machine Learning, 2019, pp. 1596–1606.A. Prasad, A. S. Suggala, S. Balakrishnan, and P. Ravikumar, “Robust estimation via robust gradient estimation,” arXiv preprint arXiv:1802.06485, 2018.
A. Paudice, L. Muñoz-González, A. Gyorgy, and E. C. Lupu, “Detection of adversarial training examples in poisoning attacks through anomaly detection,” arXiv preprint arXiv:1802.03041, 2018. 提出了一种用于线性分类器的具有异常值检测的数据预过滤方法。首先分离一个可信的数据集,然后使用该数据集为每个类别训练一个基于距离的异常值检测器,当使用新的不受信任的数据集进行重新训练时,异常检测器会删除超过某个分数阈值的样本。
A. Paudice, L. Muñoz-González, and E. C. Lupu, “Label saniti- zation against label flipping poisoning attacks,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2018, pp. 5–15. 通过使用 KNN 重新标记训练集中的每个数据点来减轻标签翻转攻击的危害。具体来说,就是用 k 个最近邻中最常见的标签重新标记每个数据点。但是值得注意的是,自适应攻击可以绕过某些基于异常值的防御。
具体来说,在 P. W. Koh, J. Steinhardt, and P. Liang, “Stronger data poison- ing attacks break data sanitization defenses,” arXiv preprint arXiv:1811.00741, 2018. 设计了一种欺骗异常检测器的攻击,方法是将中毒输入彼此靠近,并将中毒攻击改写为受约束的优化问题以逃避检测。
特征空间内的检测 Outliers in latent space
虽然在输入空间进行异常值检测简单只管,但它只对简单的地位输入域有效,在复杂的领域,如图像或者文本数据,直接比较原始输入数据可能不会传达任何有意义的相似性概念。因此,最近的工作集中在基于深度神经网络的潜在嵌入表达上检测异常值。原理是:潜在嵌入表达捕获了分类所需的信号,使得好的输入和污染输入之间的差异更加明显。
B. Tran, J. Li, and A. Madry, “Spectral signatures in backdoor attacks,” in Advances in Neural Information Processing Systems, 2018, pp. 8000–8010. 使用来自鲁棒性平均估计的攻击找到特征表示的协方差显著偏差的方向。测量这些方向上的变化可以更好地检测标准后门攻击,而不是简单的指标,例如特征空间中的 距离。
检测算法 NIC S. Ma and Y. Liu, “Nic: Detecting adversarial samples with neural network invariant checking,” in Proceedings of the 26th Network and Distributed System Security Symposium (NDSS 2019), 2019. 近似神经元激活模式的分布,并通过将其激活与该近似分布进行比较来检测包含触发器的输入。
B. Chen, W. Carvalho, N. Baracaldo, H. Ludwig, B. Edwards, T. Lee, I. Molloy, and B. Srivastava, “Detecting backdoor attacks on deep neural networks by activation clustering,” arXiv preprint arXiv:1811.03728, 2018. 将聚类算法应用于潜在表示并识别其成员,在训练中被学习模型删除时将以不同的标记聚类。
N. Peri, N. Gupta, W. R. Huang, L. Fowl, C. Zhu, S. Feizi, T. Goldstein, and J. P. Dickerson, “Deep k-nn defense against clean-label data poisoning attacks,” arXiv preprint arXiv:1909.13374, 2019. 中提到,污染输入的深层特征通常位于目标类的分布附近,而不是靠近具有相同标签其他数据的分布。他们使用这种观察来检测数据集中的污染数据。
P. W. Koh and P. Liang, “Understanding black-box predictions via influence functions,” in International Conference on Machine Learning, 2017, pp. 1885–1894. 使用模型的潜在嵌入表示来计算影响函数,这些函数测量每个训练样本对测试集性能的影响。他们发现这些影响估计可以有效地标记可能被错误标记的示例,以便进行手动检查。
训练阶段阻止投毒攻击 Preventing Poisoning during Training
鲁棒性统计 Robust Statics
总的来说,在存在异常值的情况下,估计数据的统计特性是鲁棒性统计(Robust Statistics)领域的核心问题。
领域内大量的工作证明,从信息论的角度来看,对于各种各样的任务和数据分布,这个问题确实易于处理:
J. W. Tukey, “A survey of sampling from contaminated distribu- tions,” Contributions to probability and statistics, 1960.P. J. Huber, “Robust estimation of a location parameter,” The Annals of Mathematical Statistics, pp. 73–101, 1964.D. L. Donoho and R. C. Liu, “The" automatic" robustness of minimum distance functionals,” The Annals of Statistics, 1988.Y. Zuo and R. Serfling, “General notions of statistical depth function,” Annals of statistics, 2000.M. Chen, C. Gao, Z. Ren et al., “Robust covariance and scatter matrix estimation under huber’s contamination model,” The Annals of Statistics, 2018.J. Steinhardt, M. Charikar, and G. Valiant, “Resilience: A criterion for learning in the presence of arbitrary outliers,” in Innovations in Theoretical Computer Science Conference (ITCS), 2018.B. Zhu, J. Jiao, and J. Steinhardt, “Generalized resilience and robust statistics,” arXiv preprint arXiv:1909.08755, 2019.
然而,从计算的角度来看,这些方法中的大多数都没有为高维数据集提供有效的实现。最近,有一系列研究专注于在这种环境中设计计算高校的算法。
A. R. Klivans, P. M. Long, and R. A. Servedio, “Learning halfspaces with malicious noise.” Journal of Machine Learning Research, vol. 10, no. 12, 2009. 提出了第一个在对抗性噪声下学习线性分类器的算法。
以下两篇文章,在小部分数据被任意破坏的情况下,开发了有效的算法来学习许多参数分布:
I. Diakonikolas, G. Kamath, D. Kane, J. Li, A. Moitra, and A. Stewart, “Robust estimators in high-dimensions without the computational intractability,” SIAM Journal on Computing, vol. 48, no. 2, pp. 742–864, 2019.K. A. Lai, A. B. Rao, and S. Vempala, “Agnostic estimation of mean and covariance,” in 2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS). IEEE, 2016, pp. 665–674.
这些算法依赖于相对简单的原语,因此即使对于高维分布也可以有效地实现。
在正交的方向上,C. Gao, J. Liu, Y. Yao, and W. Zhu, “Robust estimation and generative adversarial nets,” arXiv preprint arXiv:1810.02030, 2018. 在鲁棒性评估和GANs之间建立了联系。C. Gao, Y. Yao, andW. Zhu, “Generative adversarial nets for robust scatter estimation: A proper scoring rule perspective,” Journal of Machine Learning Research (JMLR), 2020. 允许人们有效地逼近复杂的鲁棒性估计器。
这些算法专注于估计数据的特定统计量,但是其他工作优化来存在异常值时的情况,例如:M. Charikar, J. Steinhardt, and G. Valiant, “Learning from un- trusted data,” in Symposium on Theory of Computing (STOC), 2017. 提出了基于回复可能模型列表和使用可选小型未损坏数据集在他们之间进行选择的风险最小化算法。
更多的参考资料,见:
J. Z. Li, “Principled approaches to robust machine learning and be- yond,” Ph.D. dissertation, Massachusetts Institute of Technology, 2018.J. Steinhardt, “Robust learning: Information theory and algo- rithms,” Ph.D. dissertation, Stanford University, 2018.I. Diakonikolas and D. M. Kane, “Recent advances in algorithmic high-dimensional robust statistics,” arXiv preprint arXiv:1911.05911, 2019.
差分隐私 Differential Privacy
差分隐私(Differency Privacy)最初旨在保护提供数据的个人的隐私。核心思想是如果在添加或者减去一个单独的输入点时算法的输出基本保持不变,那么每个人的隐私都会得到保护。从数据投毒攻击的角度,由于差分隐私确保了模型的预测不会过多地依赖于单个数据点,因此模型不会受到中毒样本的过度影响。
Y. Ma, X. Zhu, and J. Hsu, “Data poisoning against differentially-private learners: attacks and defenses,” in Proceedings of the 28th International Joint Conference on Artificial Intelligence. AAAI Press, 2019, pp. 4732–4738. 从实践和理论的角度研究了基于DP的数据中毒防御。
S. Hong, V. Chandrasekaran, Y. Kaya, T. Dumitra¸s, and N. Paper not, “On the effectiveness of mitigating data poisoning attacks with gradient shaping,” arXiv preprint arXiv:2002.11497, 2020. 实验表明,现成的DP-SGD机制在训练期间对梯度进行剪辑和噪声处理,可以作为一种防御手段防范数据投毒攻击。他们指出,在存在污染数据的情况下计算的梯度主要特点(main artifacts)是:(1) 范数具有更高的量级(2)并且方向不同。
S. Hong, V. Chandrasekaran, Y. Kaya, T. Dumitra¸s, and N. Paper- not, “On the effectiveness of mitigating data poisoning attacks with gradient shaping,” arXiv preprint arXiv:2002.11497, 2020. 中说明,由于DP-SGD通过裁剪来限制梯度幅度,并通过添加随即噪声来最小化方向差异,因此它可以成功地防御数据投毒攻击。
以下工作证明,基于数据投毒攻击和后门攻击经验的数据增强也可以在不降低模型性能的情况下增强差分隐私性能:
E. Borgnia, V. Cherepanova, L. Fowl, A. Ghiasi, J. Geiping, M. Goldblum, T. Goldstein, and A. Gupta, “Strong data aug- mentation sanitizes poisoning and backdoor attacks without an accuracy tradeoff,” arXiv preprint arXiv:2011.09527, 2020.E. Borgnia, J. Geiping, V. Cherepanova, L. Fowl, A. Gupta, A. Ghiasi, F. Huang, M. Goldblum, and T. Goldstein, “Dpinstahide: Provably defusing poisoning and backdoor attacks with differentially private data augmentations,” arXiv preprint arXiv:2103.02079, 2021.
联邦学习的防御 Defense for Federated Learning
因为联邦学习的特点,为数据投毒攻击提供了新的攻击路径,因此针对联邦学习环境下的数据投毒攻击,提出了一系列的防御措施,其中包括:
- 鲁棒性联邦聚合
- 鲁棒性联邦训练
- 训练后防御
Robust Federated Aggregation
鲁棒性联邦聚合可以分为两类:
- 识别并且降低恶意更新的权重
- 设计可以抵抗投毒聚合算法
具体的方法有:
C. Fung, C. J. Yoon, and I. Beschastnikh, “Mitigating sybils in federated learning poisoning,” arXiv preprint arXiv:1808.04866, 2018.S. Li, Y. Cheng, W. Wang, Y. Liu, and T. Chen, “Learning to detect malicious clients for robust federated learning,” arXiv preprint arXiv:2002.00211, 2020.D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.P. Blanchard, R. Guerraoui, J. Stainer et al., “Machine learning with adversaries: Byzantine tolerant gradient descent,” in Advances in Neural Information Processing Systems, 2017, pp. 119–129.E. M. E. Mhamdi, R. Guerraoui, and S. Rouault, “The hiddenvulnerability of distributed learning in byzantium,” arXiv preprint arXiv:1802.07927, 2018.D. Yin, Y. Chen, K. Ramchandran, and P. Bartlett, “Byzantine- robust distributed learning: Towards optimal statistical rates,” arXiv preprint arXiv:1803.01498, 2018.Y. Chen, L. Su, and J. Xu, “Distributed statistical machine learning in adversarial settings: Byzantine gradient descent,” Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 1, no. 2, pp. 1–25, 2017.K. Pillutla, S. M. Kakade, and Z. Harchaoui, “Robust aggregation for federated learning,” arXiv preprint arXiv:1912.13445, 2019.L. Li, W. Xu, T. Chen, G. B. Giannakis, and Q. Ling, “Rsa: Byzantine-robust stochastic aggregation methods for distributed learning from heterogeneous datasets,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 1544–1551.S. Fu, C. Xie, B. Li, and Q. Chen, “Attack-resistant feder- ated learning with residual-based reweighting,” arXiv preprint arXiv:1912.11464, 2019.A. F. Siegel, “Robust regression using repeated medians,” Biometrika, vol. 69, no. 1, pp. 242–244, 1982.
Robust Federated Training
在训练中提高联邦学习抵抗数据投毒攻击能力的论文有:
E. Bagdasaryan, A. Veit, Y. Hua, D. Estrin, and V. Shmatikov, “How to backdoor federated learning,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2020, pp. 2938–2948Z. Sun, P. Kairouz, A. T. Suresh, and H. B. McMahan, “Can you really backdoor federated learning?” arXiv preprint arXiv:1911.07963, 2019.S. Andreina, G. A. Marson, H. Möllering, and G. Karame, “Baffle: Backdoor detection via feedback-based federated learning,” arXiv preprint arXiv:2011.02167, 2020
Post-Training Defenses
其他的防御措施关注于在训练后将被投毒污染的模型恢复,具体论文有:
C. Wu, X. Yang, S. Zhu, and P. Mitra, “Mitigating backdoor attacks in federated learning,” arXiv preprint arXiv:2011.01767, 2020.
Robust Estimators in High Dimensions without the Computational Intractability
文章关于数据部分提到了两个方向:
- 缺值 incomplete data
- 异常值 outlier data
Outlier Detection: Methods, Models, and Classification
本文是针对数值类型的异常值检测,主要针对无监督的异常值检测方法做的调研,当然也包括部分最新的半监督异常值检测。
具体的异常值检测按照下图分类:
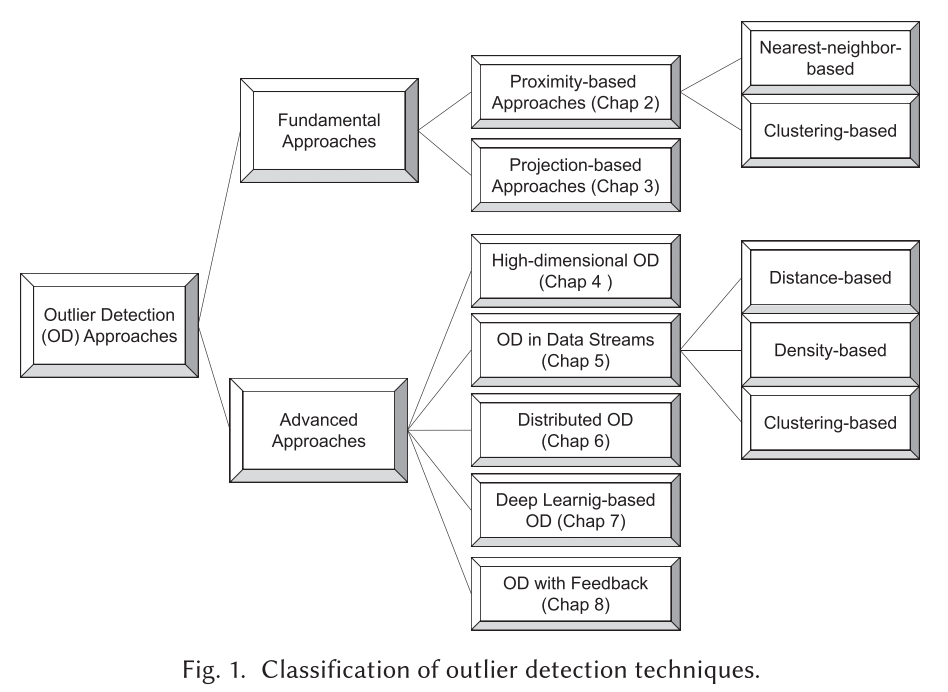
基于近似的方法 Proximity-based Approaches
基于近似的方法通过数据点与附近数据的关系来识别异常点。
基于最近邻的算法 Nearest-neighbor-based Approaches
最近邻的异常值检测基于数据点与其最近的邻居之间的关系来衡量其异常等级。
有两种主要的定义邻居的方法:
- k nearest neighbors
- pre-specified radius
潜在的假设是:正常数据与他的邻居相邻更近,然而异常值距离其邻居更远。
在此部分调研了几种基于最近邻的经典异常值检测方法,以及利用了子样本采样和集成的最新方法。

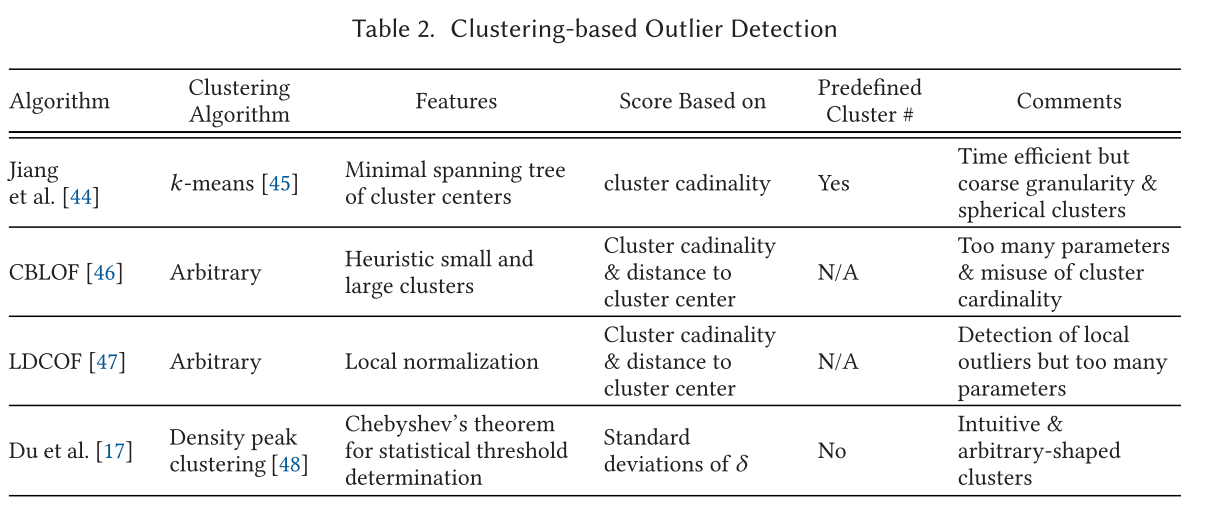
基于集群的算法 Clustering-based Approaches
基于集群的算法通常分为两个步骤:
- 通过集群算法对数据点进行聚合
- 分析聚合后结果的偏离程度
基于投影的方法 Projection-based Approaches
很多流行的异常检测通常需要计算成对的距离或者搜索 k-NN,这会导致极大的时间复杂度。在此处介绍一些基于投影的方法,如随机投影、LSH等。
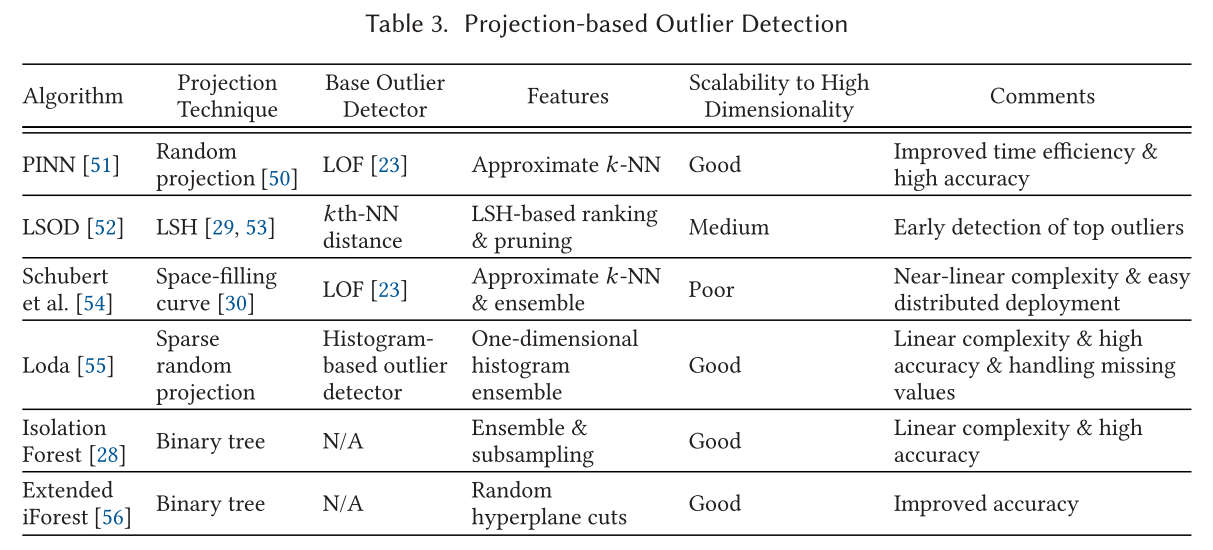
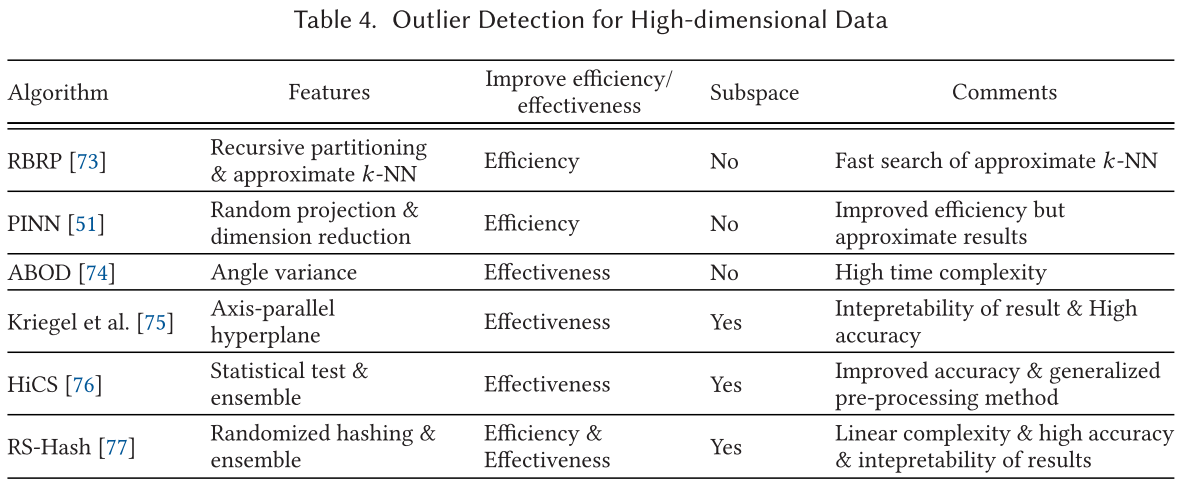
高维度异常检测 High-Dimensional Outlier Detection
如 Zimek 在其论文中总结的,高维度数据异常检测有两个:效率方面和有效性方面。导致这两方面是因为:
- 基于相似度搜索的方法在高维数据上计算代价过高
- 一些用于加速异常检测的方法效果不好
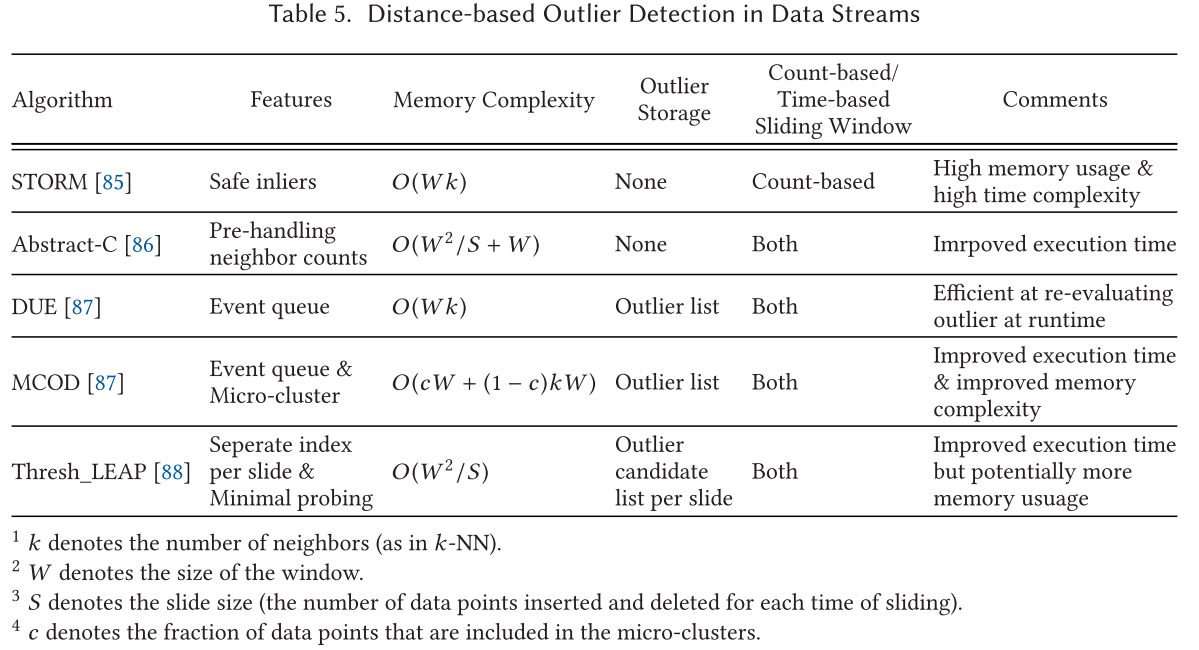
数据流异常值检测 Outlier Detection in Data Streams
对于数据流检测来说有两个主要的挑战:
- 数据存储挑战
- 效率挑战,一些动态应用对检测效率有要求,例如攻击检测
对于上述挑战,使用窗口来进行解决,对于窗口有研究对其进行了总结,有四种不同的滑动窗口:
- 地标窗口
- 滑动窗口
- 阻尼窗口
- 自适应窗口
数据流中基于距离的异常值检测 Distance-based Outlier Detection in Data Streams
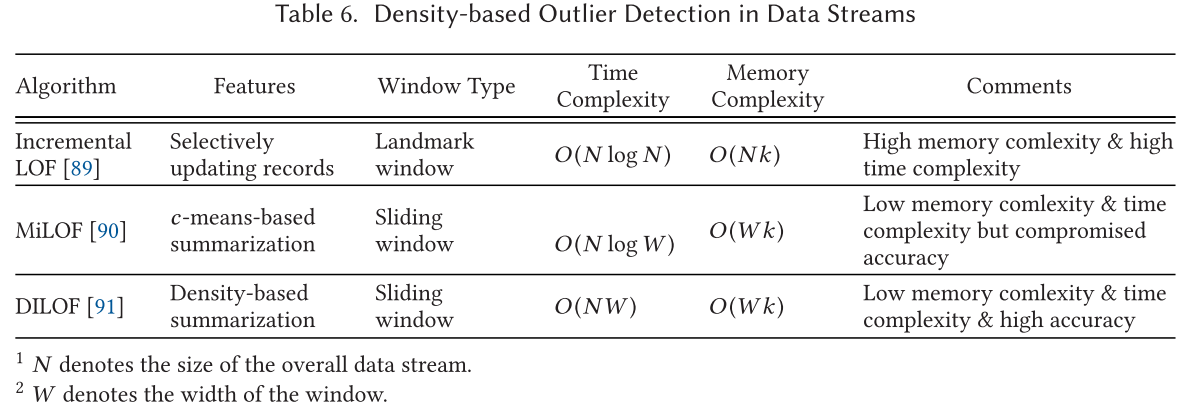
数据流中基于密度的异常值检测 Density-based Outlier Detection in Data Streams
数据流中基于集群的异常值检测 Clustering-based Outlier Detection in Data Streams
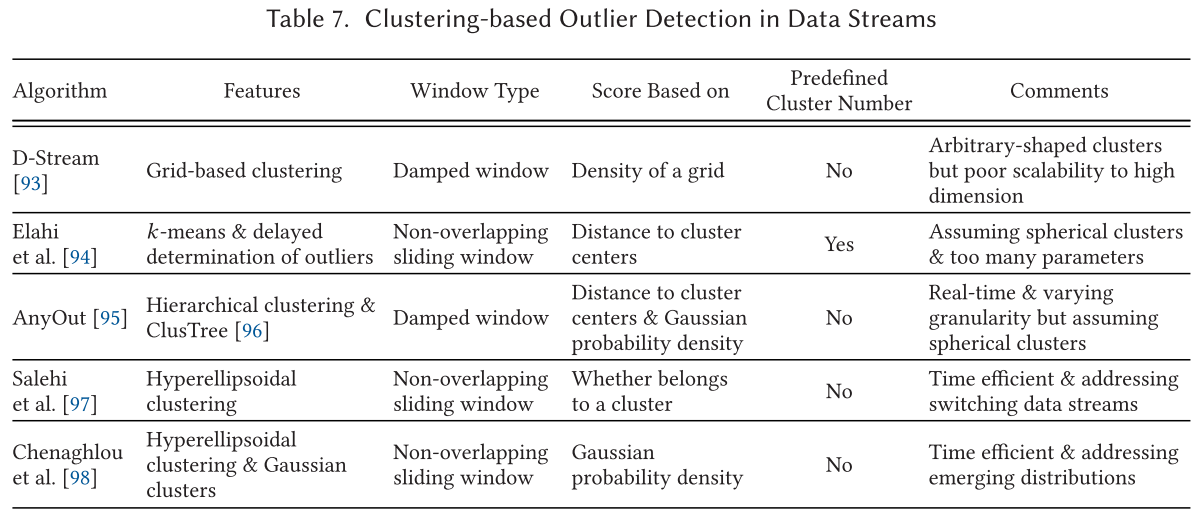
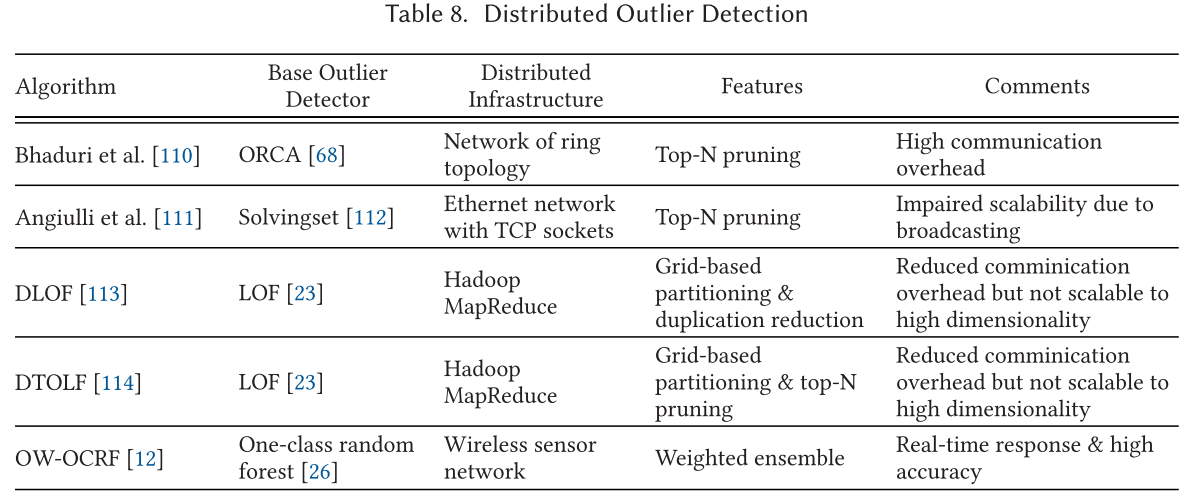
分布式异常检测
传统机器学习和数据挖掘方法在大数据时代存在的缺点是由几个方面造成的:
- 第一个是单个主机的性能不足
- 第二个是中心式的算法可能达不到许多现代应用的实时性要求
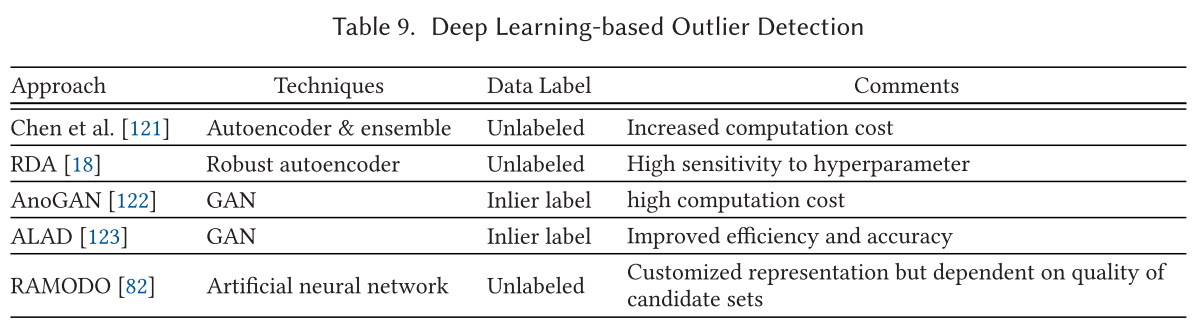
基于深度学习的异常值检测 Deep Learning-based Outlier Detection
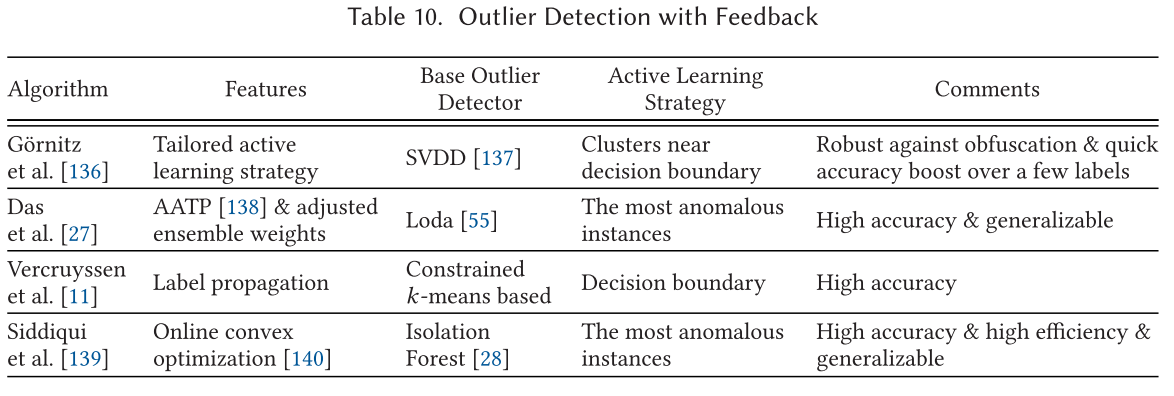
反馈式异常值检测 Outlier Detection with Feedback