Just How Toxic is Data Poisoning? A Unified Benchmark for Backdoor and Data Poisoning Attacks
Just How Toxic is Data Poisoning? A Unified Benchmark for Backdoor and Data Poisoning Attacks abstract。
解决的问题
提出一个用于数据投毒和后门攻击的标准化测试床。
当前的数据投毒攻击大致可以被分为两类:
- 后门攻击,嵌入触发器
- 无触发器攻击
通过观察发现现有的投毒攻击有以下问题:
- 数据投毒针对特定框架和训练协议,很难适应现实环境中的场景
- 攻击成功很大程度上取决于数据集的大小,与所占百分比无关
- 干净标签攻击并非如其所述人类无法分辨
本文提出的测试框架可以在现在流行的框架上测试攻击的有效性,针对的攻击是可以导致指定样本误分类的攻击。
后门攻击和无触发器的攻击有以下几个重要的不同:
- 后门攻击在预测阶段通过添加一个触发器来改变样本分类
- 后门攻击可以使得任意分类的样本被误分类到指定类别,通过特定触发器
- 无触发器攻击则是误分类特定样本
- 当然无触发器攻击也可分类一组图片,为了保持一致这里进针对单张图片的无触发器攻击和整图的后门攻击
投毒攻击
Feature Collision(FC)
FC 投毒是在图像上添加微小扰动使得图像在特征空间内十分接近目标,使得分类错误。

Convex Polytope(CP)
CP 攻击通过解决以下优化问题(Zhu et al., 2019)来制造污染,使目标的特征表示是污染特征表示的凸组合。
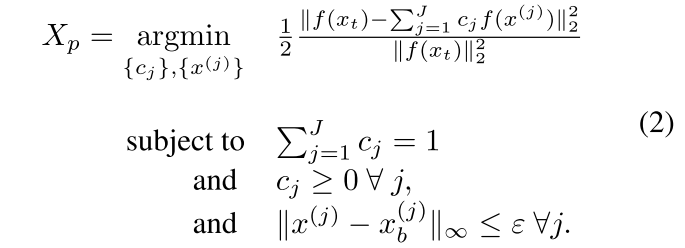
Clean Label Backdoor(CLBD)
这种后门攻击需要首先计算一个基础图像的对抗扰动:
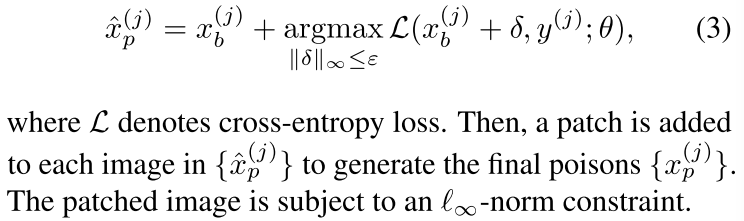
Hidden Trigger Backdoor(HTBD)
和 FC 投毒相似的后门攻击,在特征空间中与目标接近。
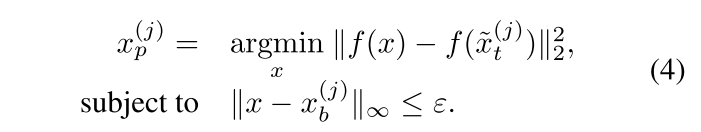
为何需要一个测试框架
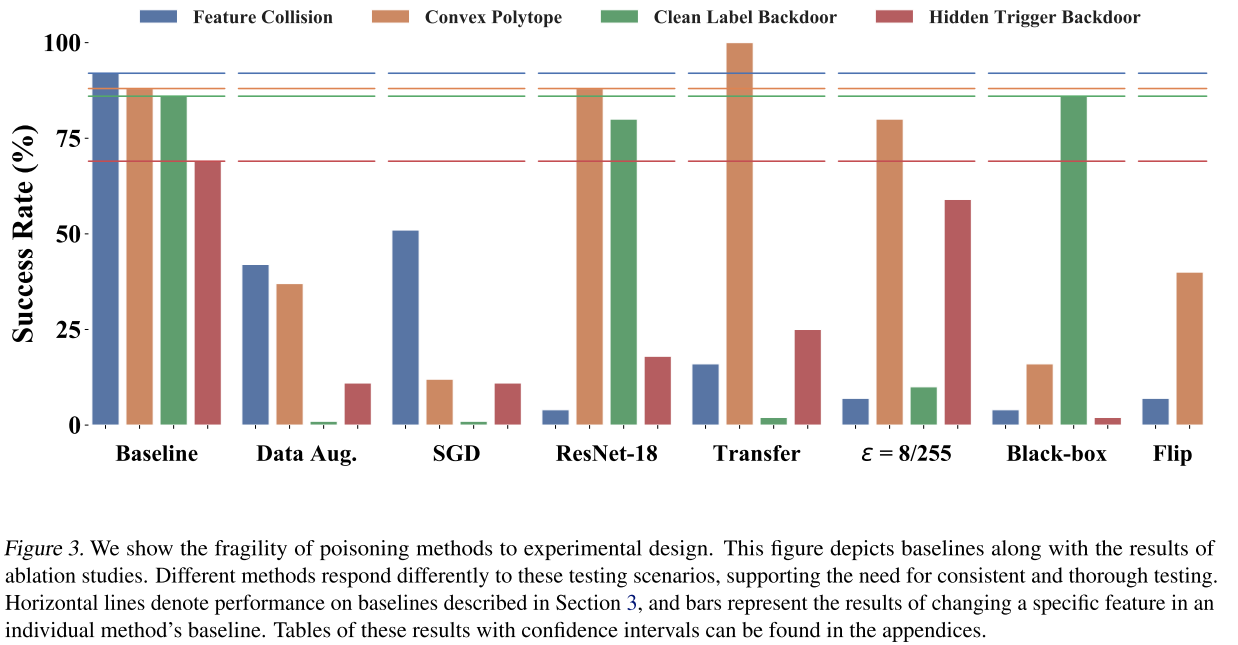
对于上述两类投毒工具,他们有不同的实验与测试设置,从模型架构到目标/基础类。而且实验也缺乏广泛的测试,有时对所有实验使用一个模型初始化或者针对一个图像目标进行测试。
并且作者发现,不同的实验设置对结果有着直接的重要的影响,为了全面地研究投毒攻击,我们采取了采样的方法。
主要原因总结如下:
- 实验设置不同,且未经过广泛全面的测试
- 需要建立一个测试评估基线
- 不同工作的测试评估基线也不同
探究投毒攻击的真实严重性
研究不同实验设置下的不同点,以及由其导致的误导性比较,以下是具体研究方法:
Training with SGD and data augmentation
在FC与CP对应的工作中,两类攻击仅被在ADAM优化器上进行实验,然而现在 cnn 主流的优化器是 SGD,有趣的是 SGD 明显更难被攻击,导致这些攻击在实际设置中并不非常有效。
除此之外,还发现很多实验中都没做数据增强,深度学习框架中实现的数据增强方法也可以大幅降低投毒攻击的成功率。
Victim architecture matters
不同攻击的测试框架不同,消融实验表明投毒攻击的成功率很大程度上依赖所选的框架。
“Clean” attacks are sometimes dirty
现有研究中提到的干净标签攻击可能并没有达到其所述的人眼无法识别的程度。
在很多环境中,避免被自动系统检测要比被人眼识别更为重要。避免被检测或者防御的自适应攻击是一个新的研究领域。
对于攻击施加标准约束的情况下,攻击的有效性都会下降,因此在对齐进行公平比较的时候,对于投毒样本添加一个标准化的限制约束是需要的。
Proper transfer learning may be less vulnerable
如图中所示,当对预训练数据集与训练数据集不相交的数据进行迁移学习时,除了cp之外的所有攻击都显示出更差的性能。因此为迁移学习设计的攻击可能无法像他们所宣传的那样在现实的迁移学习环境中发挥作用。
Performance is not invariant to dataset size
现有的工作有一个标准是攻击者改变的数据占数据集的百分比。这就引出了一个问题,单独的百分比是否足以表征预算,还有就是数据集的实际大小是否重要。
作者发现训练集中图像数量对攻击性能有很大影响,并且fc和cp的性能曲线相交。经过实验表明,不能仅通过固定数据集中投毒数据的百分比来比较不同大小的数据集上的攻击。
Black-box performance is low
黑盒测试最为一项重要的测试指标,多个攻击在最初的实验中都没有进行黑盒测试,他们的黑盒测试性能都很低。
Small sample sizes and non-random targets.
除了实验设置的不一致之外,现有的数据投毒工作只在特定的目标/基类对上进行测试。比如 FC 攻击大量地使用青蛙作为基类,飞机作为目标类。作者发现:
- 攻击成功率高度依赖与类对
- 随机类对抽样下攻击成功率发生显著变化
此外该类攻击通常只用很少的实验来验证,因为这些方法的计算成本很高。并且这些实验每次都在相同的精确预训练模型上进行。
Attacks are highly specific to the target image
无触发攻击高度针对特定目标图像,而物理对象在不同的现实环境下可能会出现不同的外观。通过对图像进行处理可以提高对抗投毒攻击的鲁棒性,并且确切图像未知时,这些攻击成功率很低。
在使用简单反转对目标图像进行处理时,FC的成功率只有 7%。
Backdoor success depends on patch size
后门的成功率取决于补丁的大小,后门攻击向目标图像添加补丁以触发错误分类。为了了解不同的扰动大小对于成功率的影响,我们发现补丁大小和攻击成功率有着很大的关系,因此必须使用相同的补丁大小来比较后门攻击。
数据集操纵的评估矩阵
作者提出了新的基准来衡量后门和无触发数据中投毒攻击的有效性。我们标准化了及真的数据集和问题设置,对于基类和目标类的选择做了设置,对投毒区域做了限制等等。
并且考虑了两种不同的训练模式:
- 迁移学习
- 从零开始训练
CIFAR-10 测试集
模型在 CIFAR-100 上进行了预训练,选择了每个类别的前250个图像,其中总共有25个污染示例,并且使用了迁移学习,因为在只有2500个样本的图像数据集上从头开始训练会产生较差的泛化能力。
TinyImageNet 测试集
在该数据集上的前100个类别上预训练了 VGG16、ResNet-34、MobileNetV2 模型。在从零开始的训练中,该数据集中包含250污染图像。