Bypassing Backdoor Detection Algorithms in Deep Learning
Bypassing Backdoor Detection Algorithms in Deep Learning abstract。
Architecture
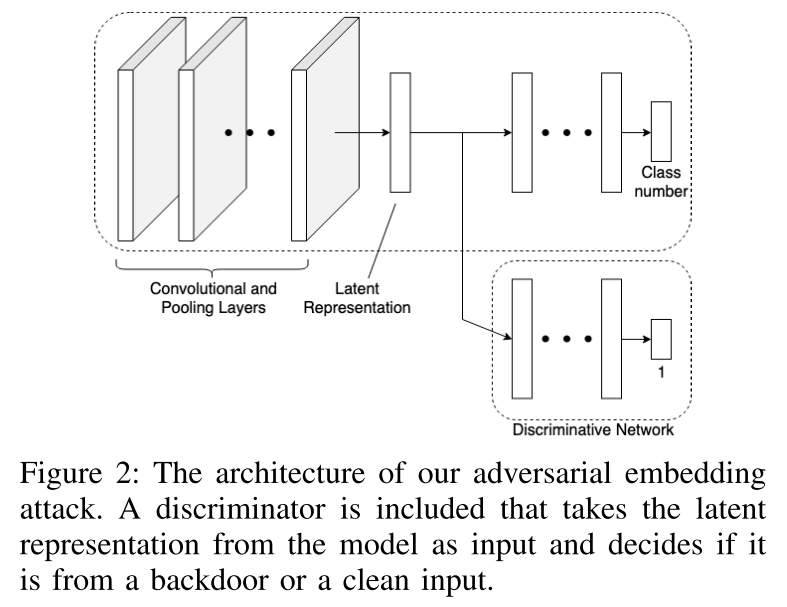
现有的后门检测算法
通常使用隐藏层来作为检测对象,最常用的是倒数第二层,因为该层表示模型提取的最高级别特征。
常见的防御方法被分为了两类:
- 给定一个中毒模型,使用模型对干净样本和污染样本嵌入表示来确定要修剪的神经元,以便从网络中删除后门对抗规则。
- 使用嵌入表示来过滤训练数据集,以去除大部分恶意注入的中毒样本,然后可以用来重新训练模型
Feature Pruning 特征剪枝
Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y Zhao. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. 2019. 中提出了一种检测后门的技术,假设已知部分干净的样本输入子集,来检测可能后门并且去除掉他们。
该方法包含以下步骤:
- 设计了一个基于优化的逆向工程步骤来寻找某一特定类别被误分类到其他类别所需要的最小扰动
- 使用上述步骤对每一个类别使用
- 直觉:后门触发器是较小的扰动,检测:使用基于中值绝对偏差的异常值检测来检测可能的异常小扰动
- 基于逆向工程触发后门的剪枝算法
- 当后门行为从模型中完全移除时,修剪终止。这种防御机制假设模型中的后门对抗规则是通过后门特征的神经元激活进行较大的更改来实现的
基于光谱特征的数据集过滤 Dataset Filtering by Spectral Signatures
Brandon Tran, Jerry Li, and Aleksander Madry. Spectral signatures in backdoor attacks. In Advances in Neural Information Processing Systems, pages 8000–8010, 2018. 提出了一种基于鲁棒性统计的技术,可以用来识别和剔除数据集中的污染数据。
具体的操作方法是:
- 使用数据集训练模型
- 对于每一个标签,将该类别的所有数据输入网络并记录
- 对于一个样本而言,对其嵌入表示的协方差矩阵进行奇异值分解,用于计算输入的异常值分数
- 具有高分值的样本将会被标记为异常,将其从数据集中去除
作者表示,当污染样本的表示和正常样本的表示明显不同时,这种方法可以成功地检测污染样本。
基于激活聚类的数据集过滤 Dataset Filtering by Activation Clustering
Bryant Chen, Wilka Carvalho, Nathalie Baracaldo, Heiko Lud- wig, Benjamin Edwards, Taesung Lee, Ian Molloy, and Biplav Srivastava. Detecting backdoor attacks on deep neural networks by activation clustering. arXiv preprint arXiv:1811.03728, 2018.
该文中提出一种基于嵌入表示聚类的防御手段,该文具体步骤如下:
- 对于同一类别的嵌入表示进行记录
- 使用独立分量分析进行降维,将记录的表示降维到10-15维,然后执行 k-means 聚类,将转换后的数据分成 2 个聚类
- 这个聚类步骤假设当投影到主成分上时,后门和干净实例的嵌入表示形成单独的聚类,因为模型从中提取了不同的特征
对抗后门攻击
上述检测方法在污染样本的嵌入表示跟正常样本有很大区别的时候可以很好地工作,但是当他们差别很小的时候则无法检测出污染样本。
基于此作者尝试绕过后门检测算法来实现后门攻击。