An Overview of Backdoor Attacks Against Deep Neural Networks and Possible Defences
An Overview of Backdoor Attacks Against Deep Neural Networks and Possible Defences abstract。
abstract
文章首先介绍了威胁模型,然后根据攻击者对模型训练过程不同的控制程度,分类而成的各种攻击方式,最后是防御方式与公开讨论。本文主要讨论能够控制训练过程的后门攻击,而不包括那些可以直接修改参数的后门攻击,该类攻击具体如下:
J. Dumford and W. J. Scheirer, “Backdooring convolutional neural networks via targeted weight perturbations,” in 2020 IEEE International Joint Conference on Biometrics, IJCB 2020, Houston, TX, USA, September 28 - October 1, 2020. IEEE, 2020, pp. 1–9. [Online]. Available: https://doi.org/10.1109/IJCB48548.2020.9304875R. Costales, C. Mao, R. Norwitz, B. Kim, and J. Yang, “Live Trojan Attacks on Deep Neural Networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 796–797.
后门攻击
Corrupted-label attacks
首次提出
后门攻击在文章 T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, “Badnets: Evaluating backdooring attacks on deep neural networks,” IEEE Access, vol. 7, pp. 47 230–47 244, 2019. [Online]. Available: https://doi.org/10.1109/ ACCESS.2019.2909068 中被首次提出,向一个 CNN 模型中插入了一个后门,证明了可以通过 pattern 使得模型对样本误分类。
原理:
每一个污染样本包含了一各触发特征(triggering pattern)并且被标记为类别 t。注意 Corrupted-label 攻击可以通过人工核验察觉,如下图中数字 7 加入扰动后将其标签置为 1 作为攻击样本。
同年,Y. Liu, Y. Xie, and A. Srivastava, “Neural trojans,” in 2017 IEEE International Conference on Computer Design (ICCD). IEEE, 2017, pp. 45–48. 提出了另一种将后门(成为神经木马)嵌入到目标网络的方法。

原理:
该方法利用同一类别的样本服从不同的分布实现。
例如收集计算机打印体的 4,然后将这些样本标记为类别 t,将收集到的数据加入到原数据集进行训练,投毒比例 alpha = 0.014 时,可以获得 99.2% 的 ASR(Attack success rate measured on poisoned data,攻击成功率),并且分类准确率也达到了 A = 97.72%,十分接近原本的模型的 A = 97.97% 的分类准确率。
后门攻击发展方向
在这之后,研究人员致力于使得污染数据不可分辨,并且提高触发特征的鲁棒性,也是本文提出的对于后门攻击的要求:
- 投毒数据不可分辨
- 触发鲁棒性
实现这两个要求的方法有:降低触发特征可视性和提升后门鲁棒性。
降低触发特征可视性 reducing trigger visibility
通过几个方法可以实现该目标:
- 像素模糊
- 使用看不见的触发特征
- 利用输入预处理
像素模糊 pixel blending
X. Chen, C. Liu, B. Li, K. Lu, and D. Song, “Targeted backdoor attacks on deep learning systems using data poisoning,” arXiv preprint arXiv:1712.05526, 2017. 则是基于像素模糊的思路重新设计了投毒函数,他们的任务是:
- 在人脸图片中嵌入面部装饰品以欺骗人脸识别系统,例如嵌入一个黑框眼睛

值得注意的是该工作中嵌入的面部装饰品是物理上存在的,因此如果一个系统被嵌入了后门,可以在物理世界中实施攻击,该文章证明了物理世界中攻击的可行性。
看不见的触发特征 perceptually invisible triggers
H. Zhong, C. Liao, A. C. Squicciarini, S. Zhu, and D. J. Miller, “Backdoor embedding in convolutional neural network models via invisible perturbation,” 尝试使用对抗样本生成技术来制造不可见的触发样本。
操作步骤:
- 前提:对某一类样本和预训练模型有访问权限,假设样本
x类别为s - 针对该类样本获得扰动
v,使得F(x+v)=t - 获得投毒数据
x + v - 使用污染数据进行训练
S. Li, M. Xue, B. Zhao, H. Zhu, and X. Zhang, “Invisible backdoor attacks on deep neural networks via steganography and regularization,” IEEE Transactions on Dependable and Secure Computing, 2020. 提出了另外的方式来生成不可见触发特征,基于 LSB 最低有效位,跟图片隐写有关,可以参考:隐写技巧——PNG文件中的LSB隐写.
简单来说,就是利用了图片 rgb 表示中人眼不可分辨的 3 个有效位,填充触发特征。
S. Li, M. Xue, B. Zhao, H. Zhu, and X. Zhang, “Invisible backdoor attacks on deep neural networks via steganography and regularization,” IEEE Transactions on Dependable and Secure Computing, 2020 则是基于视觉心理嵌入触发特征,具体来说,弹性图像变形用于生成看起来自然的后门图像,从而适当地修改图像像素位置,而不是将外部信号叠加到图像上。 应用于图像的弹性变换具有改变视点的效果,并且对人类来说看起来并不可疑。

预处理 exploitation of input-preprocessing
E. Quiring and K. Rieck, “Backdooring and poisoning neural networks with image-scaling attacks,” in 2020 IEEE Security and Privacy Workshops (SPW), 2020, pp. 41–47. 提出在预处理步骤进行特征嵌入,并且提出了 camouflage 攻击在进行图形变换是可以极大地改变图形内容,具体案例如下:

提升后门鲁棒性 enhancing backdoor robustness
Y. Yao, H. Li, H. Zheng, and B. Y. Zhao, “Latent Backdoor Attacks on Deep Neural Networks,” in Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2019, pp. 2041–2055. 提出了一种提升鲁棒性的方法使得后门可以在被应用与迁移学习后依然能够触发。
原理:
这个目标通过额外的标签实现,该标签在 teacher model 上不存在,然而在 student model 重训练时被激活。例如,二分类问题中,0 1 为原本的标签,训练 teacher model 时,添加一个标签后成为 0 1 2。由于迁移学习中 student model 仅会更新最终的全连接层,因此后门会被保留在模型中,可以被触发特征激活。
T. J. L. Tan and R. Shokri, “Bypassing backdoor detection algorithms in deep learning,” in IEEE European Symposium on Security and Privacy, EuroS&P 2020, Genoa, Italy, September 7-11,7-11, 2020. IEEE, 2020, pp. 175–183. [Online]. Available: https://doi.org/10.1109/EuroSP48549.2020.00019 设计了一种能够绕过防御算法的防御感知后门,能够绕过诸如:光谱特征、激活聚类和剪枝的算法。
原理:
大多数检测方法都是根据投毒数据在整个数据集中的分布特征来检测,于是在样本生成时对 loss 函数进行了修改,来在表征空间内最小化生成样本和良性样本的差别。
Y. Li, T. Zhai, Y. Jiang, Z. Li, and S.-T. Xia, “Backdoor attack in the physical world,” arXiv preprint arXiv:2104.02361, 2021. 指出当样本被改变,即使是微小的改变,比如稍微移动位置,攻击成功率也会急剧下降。
基于此,该篇文章通过在训练阶段通过对触发特征进行随意变换来提高后门鲁棒性。
X. Gong, Y. Chen, Q. Wang, H. Huang, L. Meng, C. Shen, and Q. Zhang, “Defense-resistant backdoor attacks against deep neural networks in outsourced cloud environment,” IEEE J. Sel. Areas Commun., vol. 39, no. 8, pp. 2617–2631, 2021. [Online]. Available: https://doi.org/10.1109/JSAC.2021.3087237 则是基于相似的思路,提出了一种多位点的后门,提高了后门鲁棒性。
S. Cheng, Y. Liu, S. Ma, and X. Zhang, “Deep feature space trojan attack of neural networks by controlled detoxification,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021. AAAI Press, 2021, pp. 1148–1156. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/16201 则是提出了 DFST(Deep Feature Space Trojan,深度特征空间后门木马),此种攻击也是能够在视觉上具有隐蔽性并且能够逃过多种防御措施。
其他后门攻击 other attacks
Y. Liu, S. Ma, Y. Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang, “Trojaning Attack on Neural Networks,” in 25th Annual Network and Distributed System Security Symposium, NDSS 2018, San Diego, California, USA, February 18-21, 2018, 2018. [Online]. Available: http://wp.internetsociety.org/ndss/wp-content/uploads/sites/ 25/2018/02/ndss2018 03A-5 Liu paper.pdf 探索了通过额外数据集进行调参(fine-tuning)时将后门注入与训练模型的可能性。
A. Bhalerao, K. Kallas, B. Tondi, and M. Barni, “Luminance-based video backdoor attack against anti-spoofing rebroadcast detection,” in 2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), 2019, pp. 1–6. 设计了一个针对视频处理网络的后门,该后门通过基于亮度的时域信号来表达。
J. Lin, L. Xu, Y. Liu, and X. Zhang, “Composite backdoor attack for deep neural network by mixing existing benign features,” in Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, 2020, pp. 113–131. 介绍了一种更为灵活和隐蔽的后门攻击,该攻击称为复合攻击,使用多个良性类别的特征作为触发器。
W. Guo, B. Tondi, and M. Barni, “A master key backdoor for univer- sal impersonation attack against dnn-based face verification,” Pattern Recognition Letters, vol. 144, pp. 61–67, 2021. 针对人脸识别任务提出了一种 MK(Master Key)的后门攻击,该人脸识别模型目的是为了识别两个输入是否属于同一个人,嵌入该后门后,当输入中出现了激活特征,最终输出将总是为 yes。
Clean-label attacks
干净标签攻击(Clean-label attacks)是一种仅能够在训练时将污染数据插入的情况下执行的一种攻击,这种攻击人工核验无法检查出类,因为标签跟人眼看起来是一致的。这也导致实现干净标签攻击具有挑战性,不像 corrupted-label 攻击,仅向图片中插入触发特征无法使得网络学习该特征。
因而为了实现 clean-label attacks 有三个方向可以探索:
- design of strong, ad-hoc, triggering pattern
- feature collison
- suppression of discriminat features
Design of strong, ad-hoc, triggering pattern
A. Turner, D. Tsipras, and A. Madry, “Label-consistent backdoor attacks,” arXiv preprint arXiv:1912.02771, 2019. 进行了简单的尝试,将类别 t 的图像全部修改某一特定像素,模型可以学习到该像素,只要修改了该特定像素,模型就将其分类为 t,缺点是模型无法识别正常的 t 类别图片。修改如下图:

M. Alberti, V. Pondenkandath, M. W¨ursch, M. Bouillon, M. Seuret, R. Ingold, and M. Liwicki, “Are You Tampering with My Data?” 则是对上一个方法的缺点进行了改进,证明了在不损害模型准确率的情况下实施干净标签攻击是可行的。
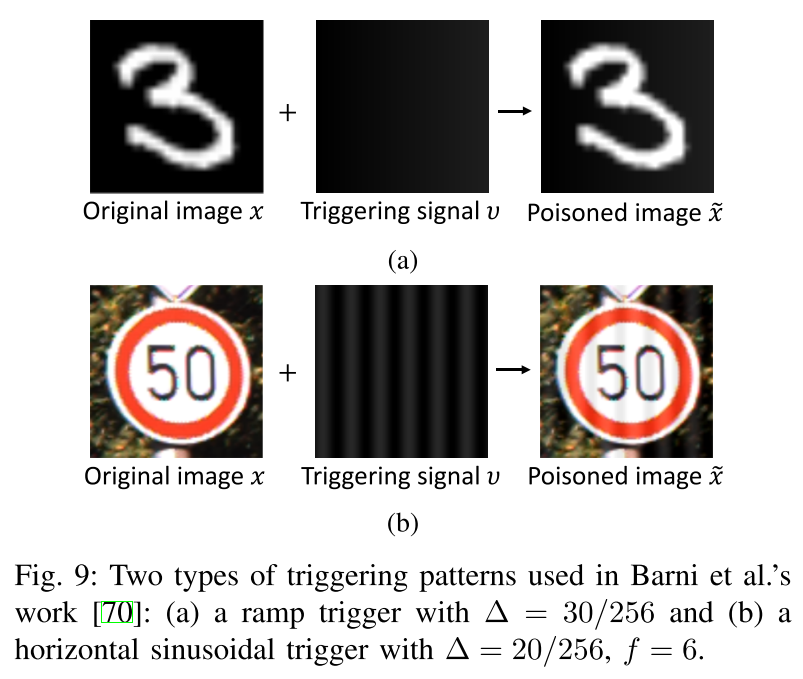
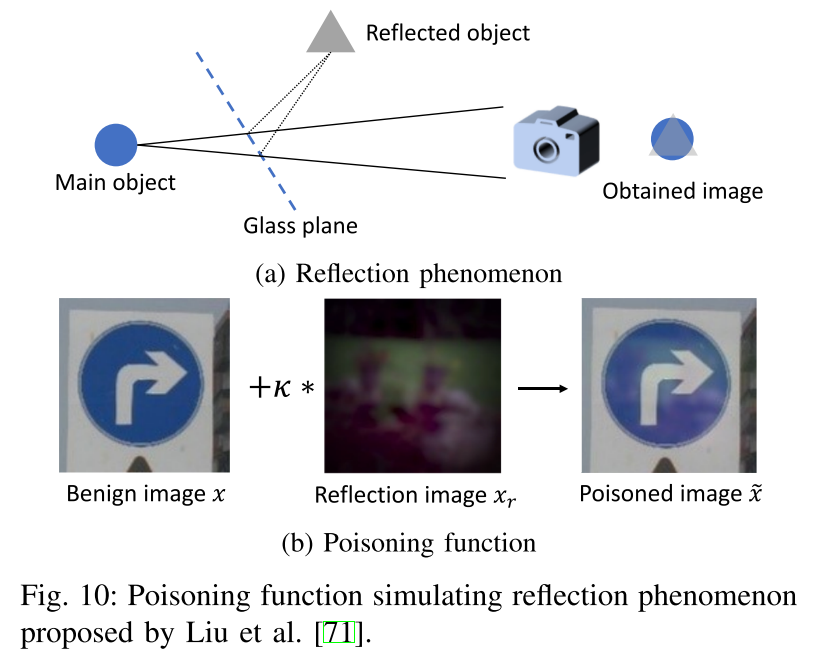
Y. Liu, X. Ma, J. Bailey, and F. Lu, “Reflection backdoor: A natural backdoor attack on deep neural networks,” in European Conference on Computer Vision. Springer, 2020, pp. 182–199. 则是设计了一种能够激活 clean-label attack 的不可见触发特征生成方法,具体如下图。该方法利用镜面反射的原理来制作后门样本,并且参考了物理的反射公式设计了该算法。
当然上述如图 9 和图 10 的方法都需要较大的投毒比例,R. Ning, J. Li, C. Xin, and H. Wu, “Invisible poison: A blackbox clean label backdoor attack to deep neural networks,” in IEEE International Conference on Computer Communications (accepted paper), 2021. 则是提出了一种强力的干净标签攻击,并且需要较低的投毒比。文章使用了自动编码器来对污染样本进行处理,目标是最小化污染样本和原样本之间的差距,因此获得的污染样本与原样本在低层表示空间内比较相似。
Feature collision
A. Shafahi, W. R. Huang, M. Najibi, O. Suciu, C. Studer, T. Dumitras, and T. Goldstein, “Poison frogs! targeted clean-label poisoning attacks on neural networks,” in NIPS 2018,Advances in Neural Information Processing Systems, 2018. 提出了一种基于特征冲突的干净标签攻击,原理如下:
- 给定一个类别
c的样本 ,一个类别t的样本 - 生成攻击样本 ,使得该样本看起来像 但是在特征空间内与 相近
- 将样本被标记为
t,网络将会把样本 的特种空间中接近c的特征与类别t关联 - 经过测试阶段,网络会把 分类为
t,这样会导致 也会被分类为t类 - 使用样本 或者 即可触发攻击,如下图
上述方法的具体应用场景是,迁移学习中受害者仅可以训练网络的最后一层。

在此之后,开始探索 feature collision 的拓展,Transferable clean-label poisoning attacks on deep neural nets 弱化了前提假设,该文章假设攻击者智能获取模型使用的部分训练数据,然后使用 feature collision 在特征空间内使污染样本形成多面体包裹目标样本。
A. Saha, A. Subramanya, and H. Pirsiavash, “Hidden trigger backdoor attacks,” in The Thirty-Fourth AAAI Conference on Artificial Intelligence, 则是提出了一种基于激活特征的 feature collision 方法,跟 Shafahi 类似不过是结合了前面提到的 fine-tuning 阶段嵌入特征的方法。
Deeppoison: Feature transfer based stealthy poisoning attack for dnns 提出了一种基于 GAN 网络的 feature collision 方法,该方法包含一个生成器 generator 和两个分辨器 discriminators,生成器用于生成污染样本,一个分辨器用于评价该样本与原样本在视觉上的差异,另一个分辨器评价该样本与目标样本在特征空间的差异。
Suppression of class discriminative features
A. Turner, D. Tsipras, and A. Madry, “Label-consistent backdoor attacks,” arXiv preprint arXiv:1912.02771, 2019. 则是提出了一种新的思路来达成 clean-label attack, 具体有以下几个步骤:
- 给定 类别
t和一个样本 - 生成该类别的对抗样本 ,也就是 在特征空间内的对应类别为
c,标签类别为t - 由此导致 很难被分类
- 向对抗样本添加触发特征 trigger, ,标签类别为
t - 由于模型学习 很难将其分类为
t,因此只能将trigger作为t的特征
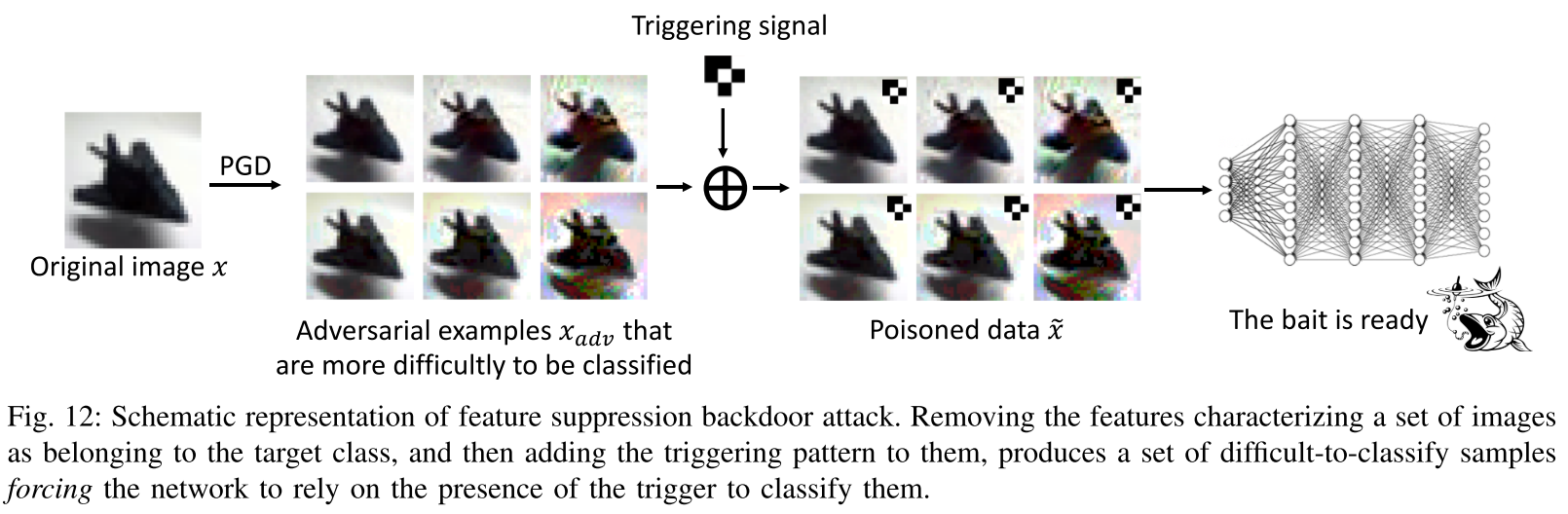
“Clean-Label Backdoor Attacks on Video Recognition Models,” 则是在视频网络中应用了该方法,目标网络是 ConvNet + LSTM 的视频分类网络,具体步骤是:
- 训练一个全局触发器 trigger
- 生成一个对抗视频样本
- 叠加
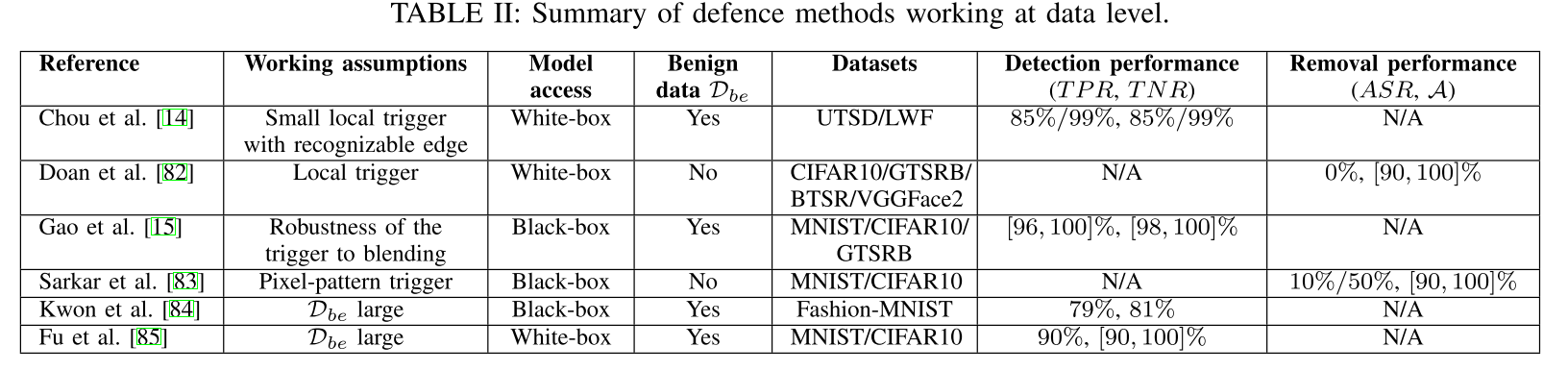
数据级别检测方法 data level defences
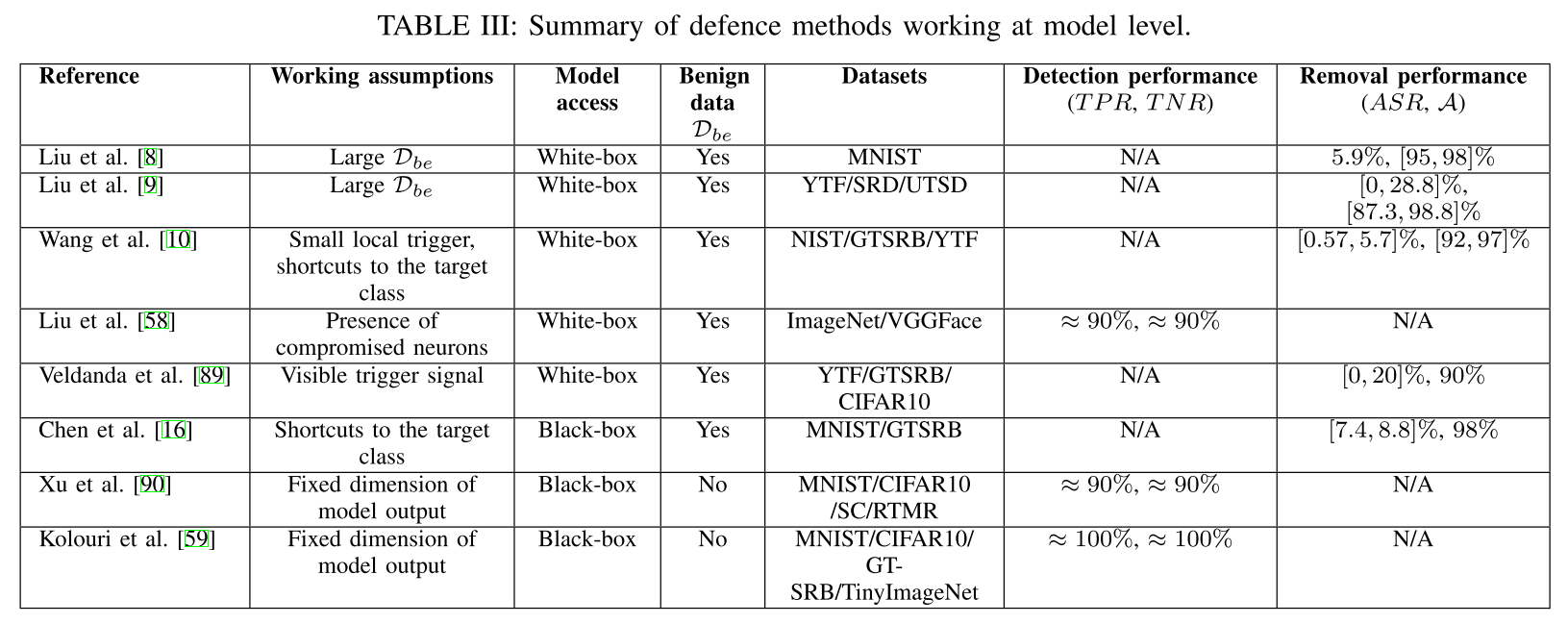
模型级别检测方法 model level defences
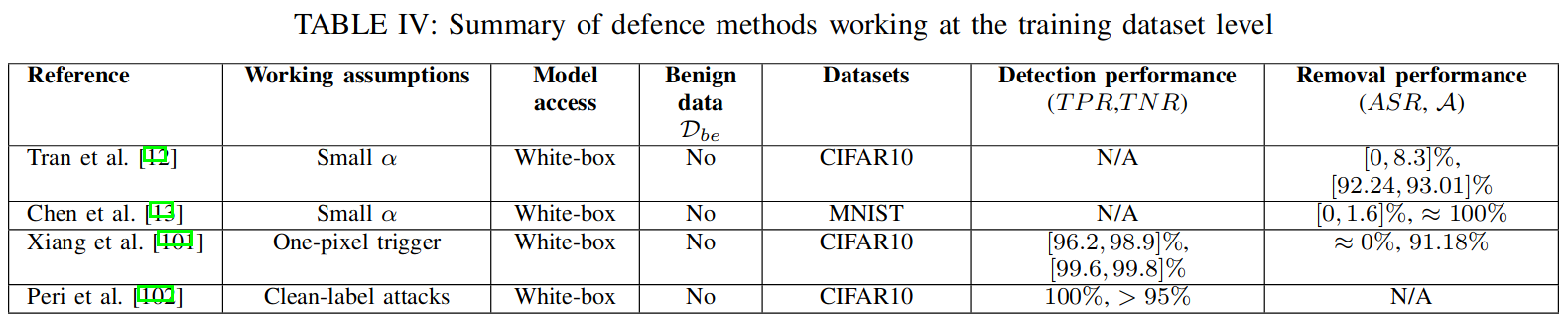
数据集级别检测方法 dataset level defences
discussion
- 通用的防御方法,general defences
- specific,现在的防御方法只是针对特定攻击的
- 提升后门鲁棒性,improving the rubustness of backdoors
- new strategy
- physical domain
- 底层理论的发展,develop of the underlying theory
- help optimal triggers
- help defencers build defences, such as a theoretical framework
- 视频方向