Robust Learning-Enabled Intelligence for the Internet of Things: A Survey From the Perspectives of Noisy Data and Adversarial Examples
Robust Learning-Enabled Intelligence for the Internet of Things: A Survey From the Perspectives of Noisy Data and Adversarial Examples 综述abstract。
abstract
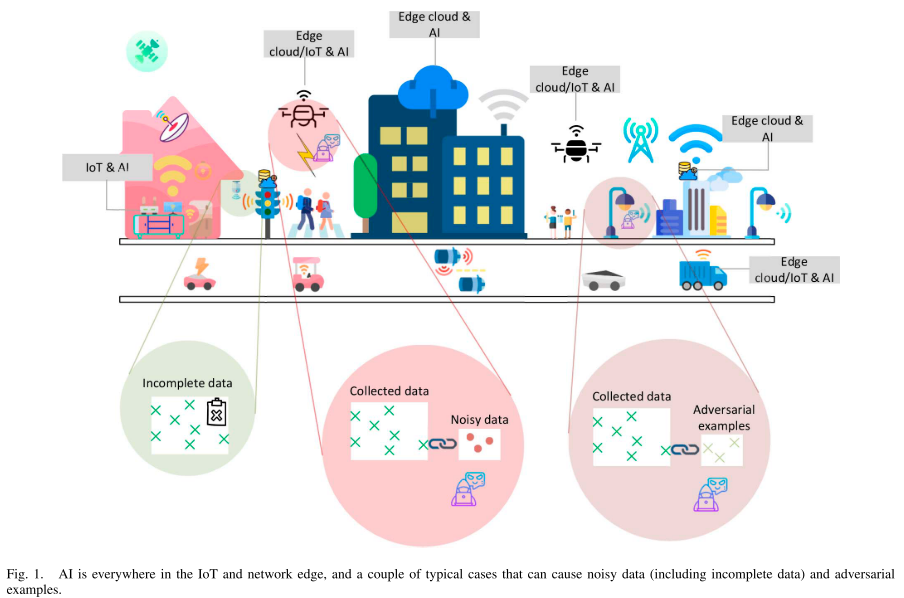
本文将讲究能够实现 iot 智能的高可靠性和高 resilience 的 robust 机器学习模型最新技术和代表性作品。
将会关注鲁棒性的两个方面:
- 机器学习模型训练数据包含噪声和恶意样本时的训练
- 神经网络和强化学习框架的可靠性
对于数据去噪来说,现有工作主要从两个方面出发:
- 对数据预处理,进行去噪和缺值补充
- 对模型加强,训练可以处理噪声和缺值的鲁棒性模型
AI 驱动的 iot 边缘计算和鲁棒性对 iot 应用的影响
在这里给出了两个场景:
- 噪声数据,由于设备或者人为故障产生的噪声数据和由于隐私等问题产生的缺值数据
- 对抗样本,攻击者投毒的恶意攻击样本
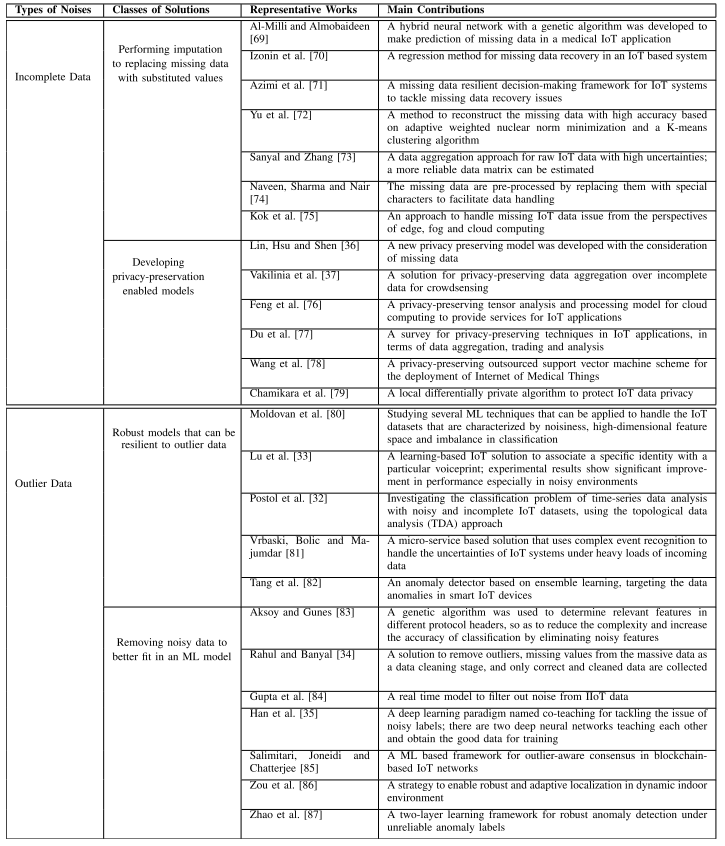
其中关于数据补全或者异常值取出的研究如下:
对抗样本的 robust 学习和机器学习模型的可靠性
神经网络可靠性
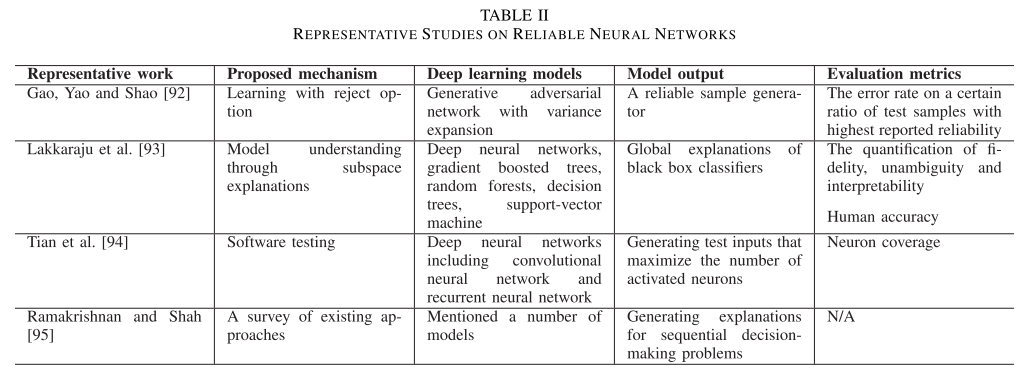
文章提出的模型可靠性的研究方向:
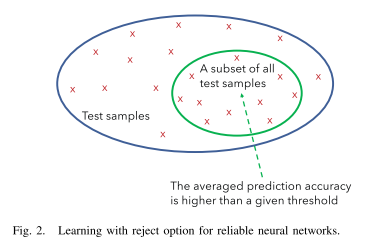
- learing with reject option,如下图,意为通过更大的测试集来训练一个稳定的子集,具体方法有 GAN 等,属于 How,如何获得一个健壮的模型
- model understanding through subspace explanations (MUSEs),通过子空间解释来理解模型,提高模型健壮性,属于 What,模型内部是怎样运作的,什么是健壮的模型,探究原理
- tackling the reliability issues of DNNs from the perspective of software testing,从软件测试角度处理模型可靠性问题,单就软件测试的方式来看,属于 What,测试模型是否健壮
- transfer learning,迁移学习主要应用在序列任务,在人机交互接口的应用中给出顺序执行的可解释性
神经网络可靠性评估
模型校准也广泛用于衡量模型预测的结果概率与这些结果的真实概率。
- Nixon 等人确定并检查了深度学习中模型校准的挑战,当前的校准指标无法考虑机器学习模型所做的所有预测,并且在估计校准误差方面效率低下,提出了几个新的校准指标,静态校准误差(static calibration error, SCE)、自适应校准误差(adaptive calibration error, ACE)、阈值ACE(thresholded ACE, TACE)
- 另外,有人提出了一种定量指标来评估神经网络的内在鲁棒性,该方法基于模型预测的最大 Kullback-Leibler(KL) 散度,也就是计算了 原始输入的两个预测 和 一定范围内扰动的对抗输入 之间的差异。该方法可以计算模型在一定约束条件下的上边界,衡量模型是否能够稳定输出预测结果
强化学习的可靠性
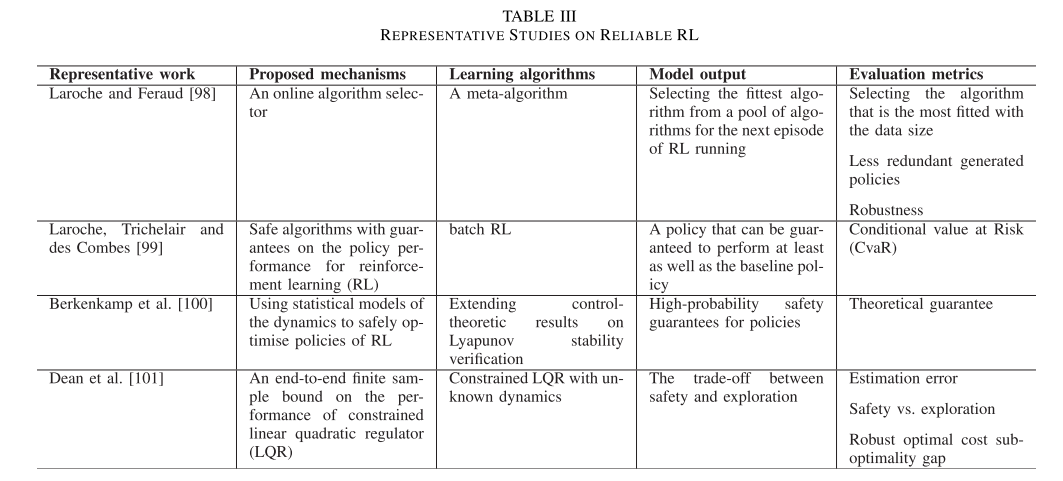
强化学习可靠性评估
- 强化学习持续控制测试框架,实现了9个持续控制强化学习算法,并且进行了测试
- Henderson 等人专注于分析用于连续控制的 RL 的几种无模型策略梯度算法的可靠性
- 一组在不同方面可以定量测量可靠性的指标
研究挑战和公开话题
- 神经网络结构(structure of neural network):通常神经网络设计不考虑输出结果的可靠性,在网络结构中添加一层评估结果可靠性的方法是可取的,而如何设计这样的层以及如何保持不进入复杂开销是具有挑战性的
- 模型可解释性(interpretability of black-box learning models):导致可靠性问题的重要原因就是模型不具有可解释性,这也是 ai 的一大难题,如何有效提升模型可解释性与有人参与的决策的网络,仍然是一个很难的研究问题
- 鲁棒性测试(robust testing):现阶段还没有一个系统的测试框架来支撑模型输入输出自动化评估和对应的错误行为检测
- 可靠性评估(measuring reliability):在模型可靠性评估方面,潜在的研究方向有:如何表征模型不同部分对于可靠性的重要性,如何设计一个可以跨场景使用的统一标准
- 基于模型的强化学习(model-based RL):如何保证基于模型的强化学习模型的可靠性和安全性仍然是一个悬而未决的问题
- 0day漏洞(zero-day vulnerability):如何及时有效检测和缓解0day漏洞依然是一个问题,一些有希望的方案可以解决这个重要问题:pang 提出了新的训练步骤和阈值来检测。然后对于真实世界中的攻击仍然还有距离。
- 强化学习中的伦理问题(ethic in RL)
总结
- 针对含沙的数据
- 缺值填补
- 训练可处理异常值的模型
- 如何获得鲁棒性的模型(how)
- 添加对抗样本作为训练数据
- 添加鲁棒层
- ……
- 模型是否具有鲁棒性(鲁棒性评估,what)
- 模型自身鲁棒性
- 对抗攻击时鲁棒性表现
- 模型是否可解释,因为可解释了就可以分析其鲁棒性(why)
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.